Abschlussarbeiten
Bachelor- und Masterarbeiten werden aus verschiedenen Forschungsbereichen des Lehrstuhls angeboten. Hierbei werden konkrete Themen in der Regel vom Lehrstuhl angeboten (s.u.) oder in Zusammenarbeit mit der/dem Studierenden definiert.
Um eine Abschlussarbeit am Lehrstuhl für Erklärbares Maschinelles Lernen zu schreiben, gelten in der Regel folgende Voraussetzungen:
- erfolgreiche Prüfung in einem Modul mit Vorlesung und Übung in DeepLearning (für Masterarbeit), Maschinelles Lernen oder Einführung in die KI
- erfolgreiche Teilnahme an einem vom Lehrstuhl angebotenen Seminar oder Projekt
Offene Abschlussarbeiten
Please refer to VC [Link] for further details.
Laufende Abschlussarbeiten
- “Investigating Detection Transformers for Implant Detection in Intraoperative X-ray Imaging" - Maximilian Rittler, betreut von Christian Ledig
- “Evaluating the Robustness of Vision Foundation Models on an ImageNet Class-Subset Using Photorealistic Images Synthesized in Unreal Engine" - Markus Leinberger, betreut von Sebastian Dörrich
- “Evaluating the Applicability of Training-Free Style Transfer for Test-Time Augmentation under Domain Shift" - Noah Ikechukwu Emmler, betreut von Sebastian Dörrich
- “Evaluating the Impact of Alternative Color Spaces on Image Classification" - Giresse Ginola Ngansop Njinkap, betreut von Sebastian Dörrich
- “Exploring the Applicability of Uncertainty Disentanglement for Medical Image Classification" - Florian Weigl, betreut von Sebastian Dörrich
- “Structure-Aware Domain Generalization via Graph Neural Networks and Foundation Model Representations for Gastric Whole Slide Image Classification" - Hannes Christian Weber, betreut von Christian Ledig
- “Post-Hoc Model Merging of Generative Experts for Privacy-Preserving Multi-Domain Medical Imaging in Foundation Model Embedding Space" - Stephanus Park, betreut von Francesco Di Salvo
Abgeschlossene Abschlussarbeiten
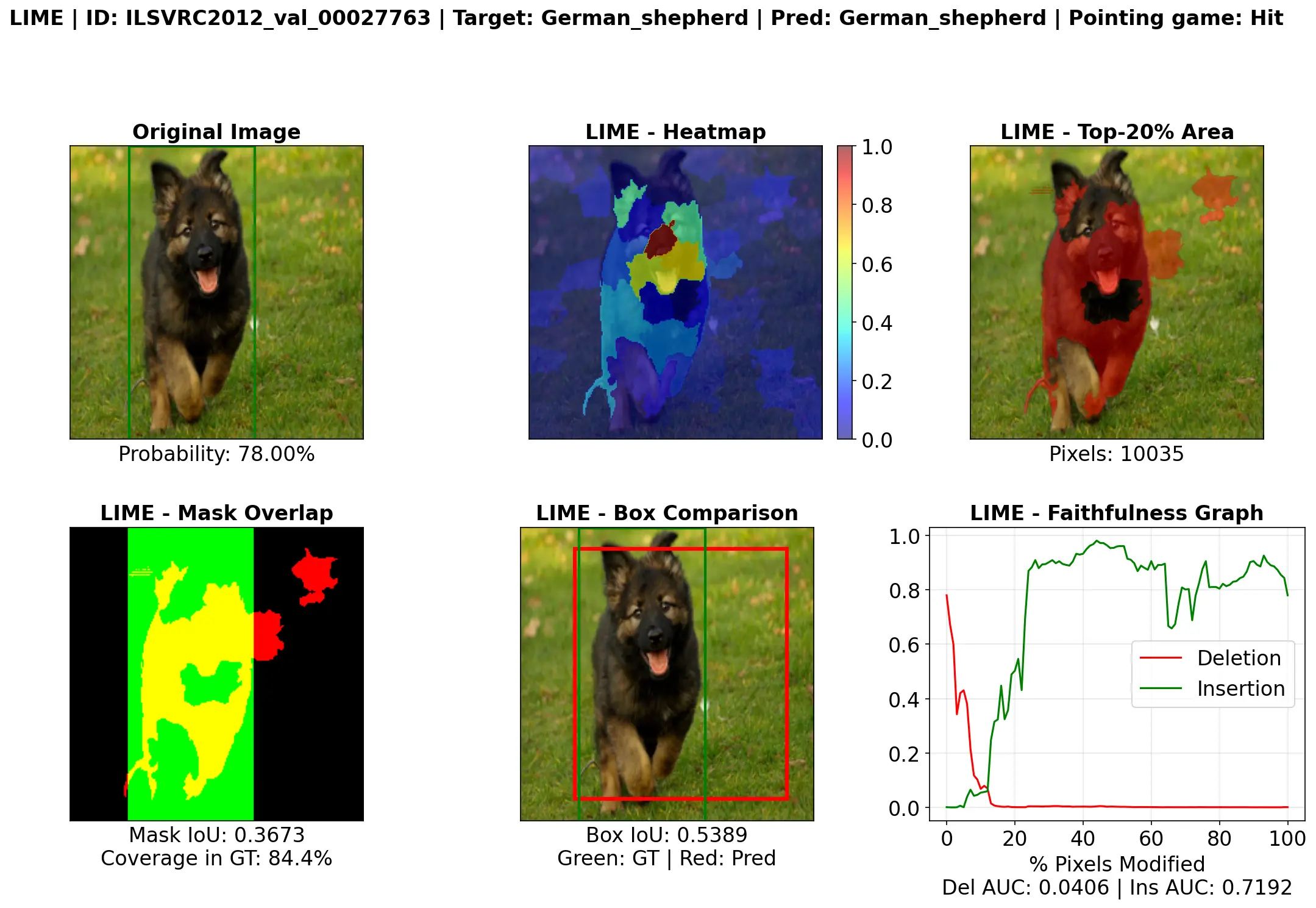
Autor: Pei Shan Keak, betreut von Sebastian Dörrich
This thesis evaluates visual explainability methods for image classification tasks using a ResNet-18 model trained on ImageNet-1k. These methods are evaluated using both qualitative and quantitative approaches. To facilitate a fair comparison between disparate output types, such as coarse heatmaps and segmented explanations, we introduce an evaluation framework that integrates an attention budget into Intersection over Union metrics by retaining the top-k% of the most important pixels. Additional metrics, including the Pointing Game and the Insertion and Deletion Area Under Curve, are implemented to measure localization and faithfulness. Qualitative analysis shows that Grad-CAM and LIME successfully identify regions where the model is focused when making its classification, such as the faces of mammals or the functional parts of artifacts. However, our study also reveals that the model has learned spurious correlations and relies on background cues in some cases. These findings demonstrate that both quantitative and qualitative evaluation approaches are necessary when investigating visual explainability to ensure that a model’s correct predictions are based on appropriate focus and reasoning. In this framework, quantitative metrics are utilized to identify patterns, which are then cross-validated through qualitative visual inspection to uncover instances of shortcut learning.
Link to thesis(3.0 MB)
Link to code

Autor: Juncheng Gong, betreut von Francesco Di Salvo
In many machine learning studies, data augmentation methods are mainly evaluated based on performance on clean in-distribution test data. However, this setting often does not reflect realistic conditions, where models may encounter corruptions, noise, or domain shifts at test time. Consequently, it is not always clear whether augmentation methods that improve clean accuracy also improve robustness and calibration under distribution shift.
This thesis investigates the effects of modern image data augmentation methods on predictive accuracy, calibration, and corruption robustness. Experiments are conducted on both natural-image datasets (CIFAR-10, CIFAR-100) and medical-image datasets (DermaMNIST, PathMNIST), using ResNet-18 and Vision Transformer architectures. To enable consistent comparisons across datasets and models, the experiments follow a three-stage protocol consisting of learning-rate selection, model training, and robustness evaluation on corruption benchmarks including CIFAR-C and MedMNIST-C.
The results show that improvements on clean test data do not necessarily correspond to improved robustness under distribution shift. In addition, the effectiveness of augmentation methods varies across datasets and model architectures. Differences in calibration behavior are also observed, indicating that confidence estimates may degrade even when predictive accuracy remains relatively stable. Overall, the experiments highlight the importance of evaluating augmentation methods beyond standard clean benchmarks when assessing model reliability.
Link to thesis (4.1 MB)
Link to code
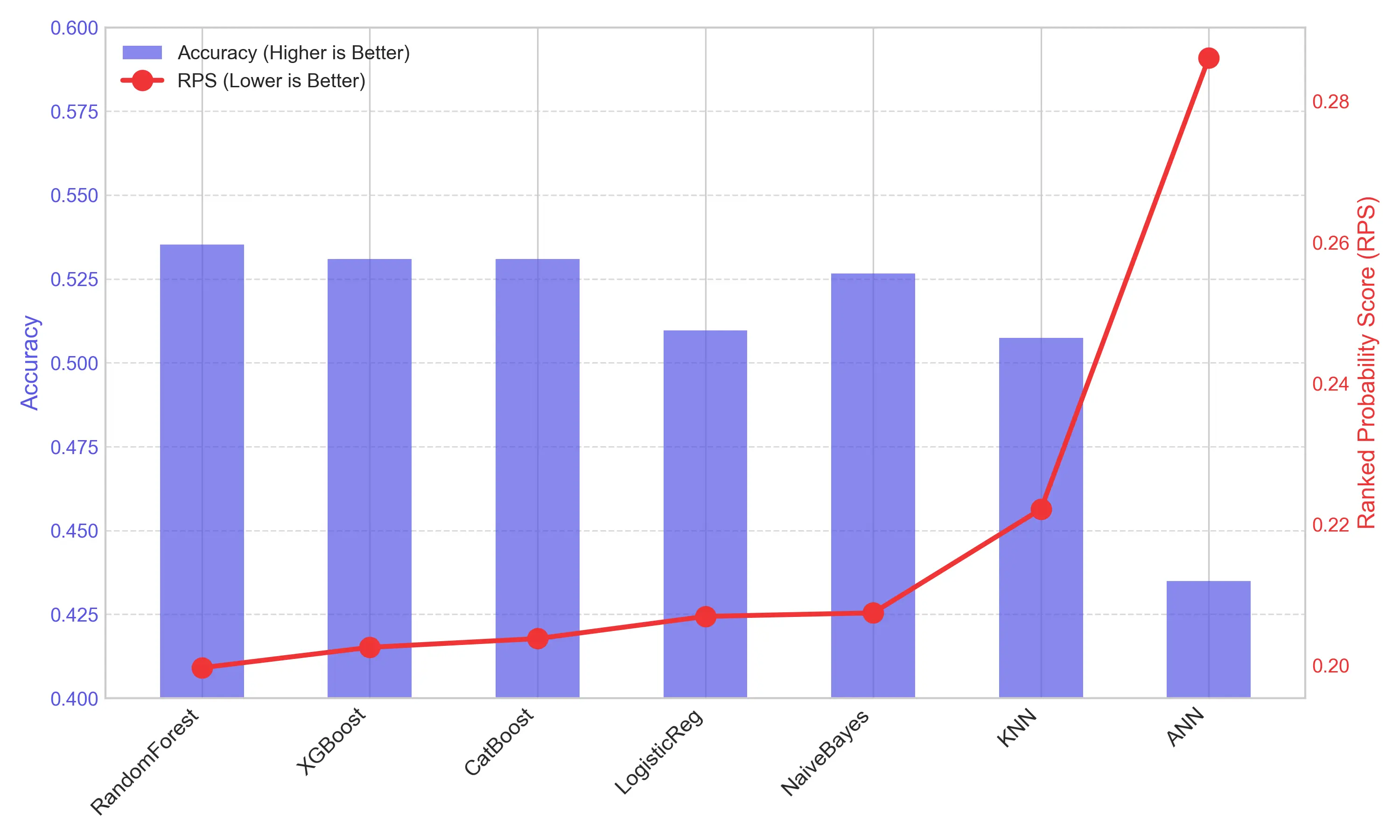
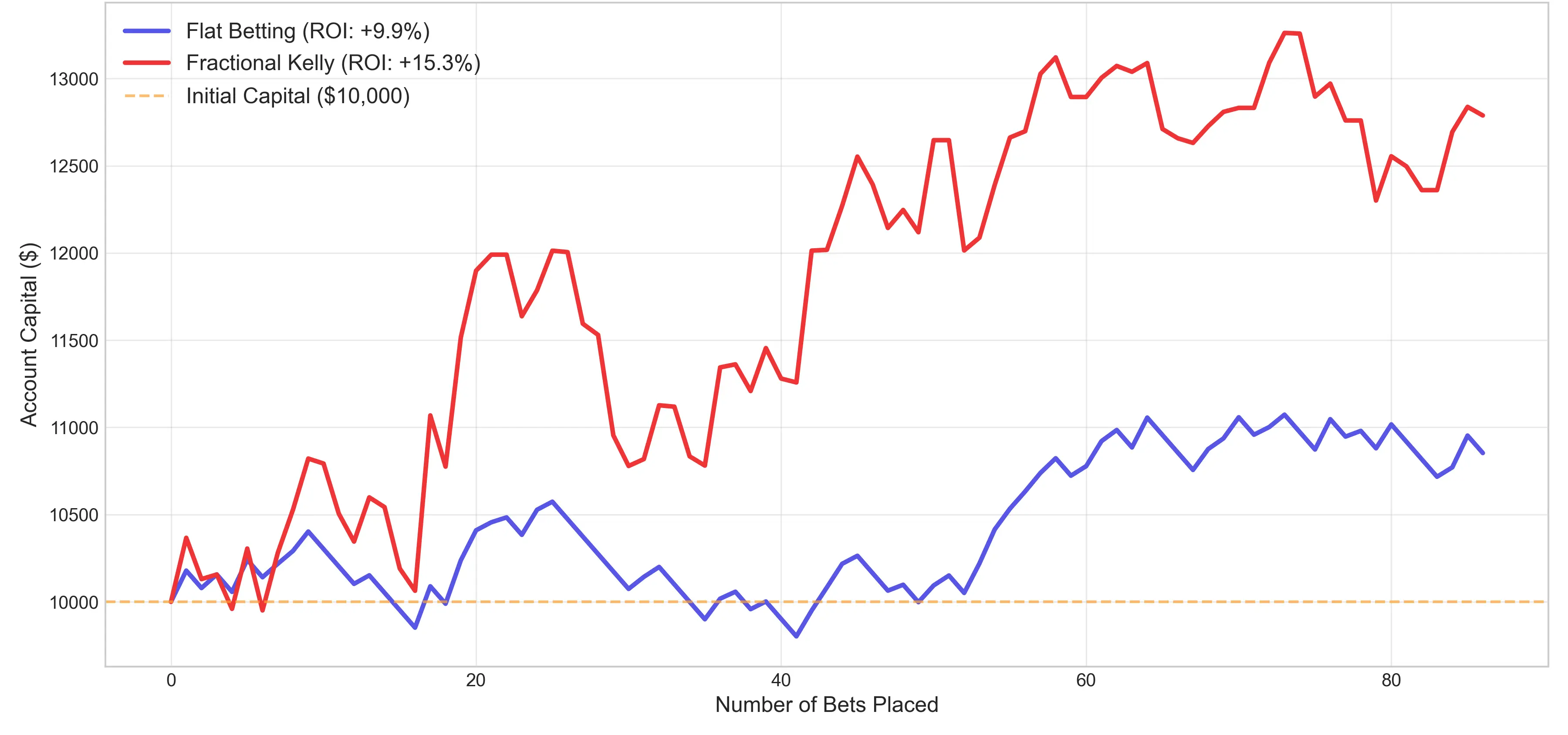
Autor: Di Bao, betreut von Prof. Dr. Christian Ledig
This research addresses the challenge of predictive modeling and strategic capital allocation within the highly efficient English Premier League betting market. The project transitions from raw historical data to a data-driven decision-making framework, integrating machine learning with financial engineering.
The core research question: Can a machine learning ensemble, combined with systematic bankroll management, identify profitable strategies in the sports betting market?
To answer this, I developed a multi-stage pipeline:
- A Feature Engineering Process with a Dual-Track Feature Selection Mechanism: Including multiple feature engineerings to capture team momentum and selecting the features with RFE and PCA.
- Multi-Model Evaluation: Using Random Forest model, achieving a Ranked Probability Score of 0.1997.
- An Empirical Comparison of Betting Strategy Profitability: Analyzing variable methods to find the best way to capture value bets.
- Back-Testing with Dynamic Capital Management: Through the Fractional Kelly Criterion, converting probabilistic edges into sustainable 15.3% ROI, while strictly controlling Maximum Drawdown.
- Walk-Forward Validation framework: To simulate a realistic investment environment.
Several findings emerged from the pipeline. Random Forest model successfully captured complex tactical patterns and matched the efficiency of multi-billion dollar bookmaker benchmarks. The integretion strategy focuses on the most likely outcomes through a specialized value filter, achieved a 9.9% ROI while maintaining a low maximum drawdown of -7.3%. Fractional Kelly Criterion functioned as a dual-action engine: it compounded absolute returns and acted as a secondary quality filter by rejecting negative-expected-value bets, ultimately elevating the system’s ROI to 15.3%.
The results demonstrate that while the betting market is largely efficient, systematic algorithmic approaches can yield risk-adjusted returns that showed great potential in sports betting.
Link to thesis(1.7 MB)
Link to code

Autor: Roza Gaisina, betreut von Sebastian Dörrich
Understanding how image classification models utilize visual information remains a central challenge in computer vision Geirhos et al. (2018). This thesis investigates whether object-centric data augmentation can serve as a structured framework for analyzing model behavior under controlled visual manipulations. To this end, a modular augmentation pipeline, sam2aug, is developed that integrates segmentation, inpainting, and object-level transformations. The pipeline enables the generation of controlled datasets that isolate specific visual factors, including texture, shape, background context, and object scale.
Experiments on ImageNet-pretrained convolutional neural networks and Vision Transformers reveal consistent trends across all settings. Under standard conditions, model predictions are largely driven by texture cues. However, when structural information is preserved or emphasized, the proportion of shape-consistent predictions increases. In addition, Vision Transformer models (in particular, ViT-Base) exhibit greater stability under contextual and geometric perturbations than convolutional architectures. Additional experiments show that model predictions are sensitive to background context and object scale, with performance decreasing under distribution shifts and size reductions.
Overall, the results demonstrate that object-centric augmentation provides a flexible and interpretable framework for analyzing model behavior and offers new insights into the robustness and decision strategies of modern vision models.
Link to thesis(10.8 MB, 71 Seiten)
Link to code
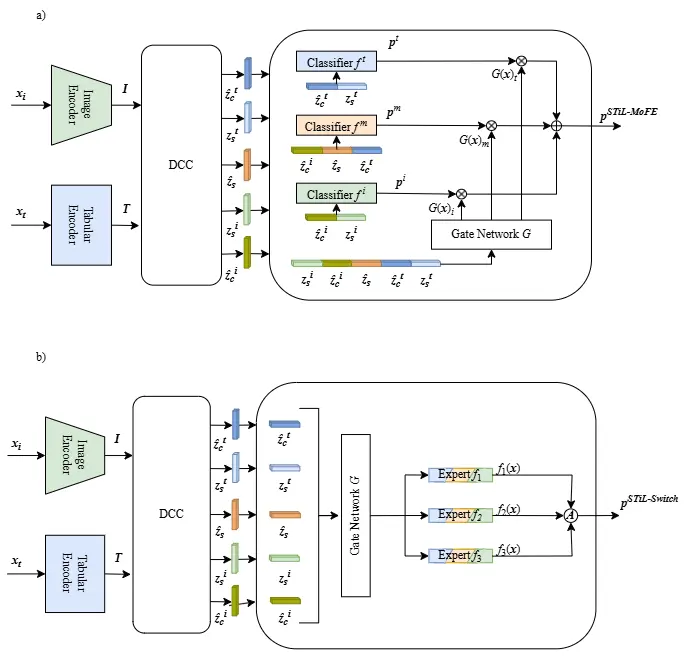
Autor: Kevin Gutjahr, betreut von Franceso Di Salvo
In the literature, machine learning models are typically trained and tested on datasets with similar feature distributions, as this setting allows them to perform most effectively. However, this assumption rarely holds in real-world scenarios, where deployed models often encounter data that differs from the training distribution. In medical applications in particular, factors such as patient demographics, varying scanner settings, and missing data can introduce significant distribution shifts, potentially leading to incorrect predictions with serious consequences.
This thesis investigates the effectiveness of different augmentation strategies to mitigate the impact of such distribution shifts. In particular, it examines both state-of-the-art latent embedding augmentation techniques and the integration of the Mixture-of-Experts (MoE) framework into the STiL architecture. The STiL architecture is designed to extract and leverage both modality-specific and modality-shared information. Building on this, two MoE-based variants are explored: STiL-MoFE, where classifiers receive a fixed set of inputs, and STiL-Switch, where input tokens are dynamically routed by a gating network. The results indicate that integrating the Mixture-of-Experts framework can improve performance under distribution shifts, although some model instabilities are observed.
Link to thesis(9.1 MB, 87 Seiten)
Link to code
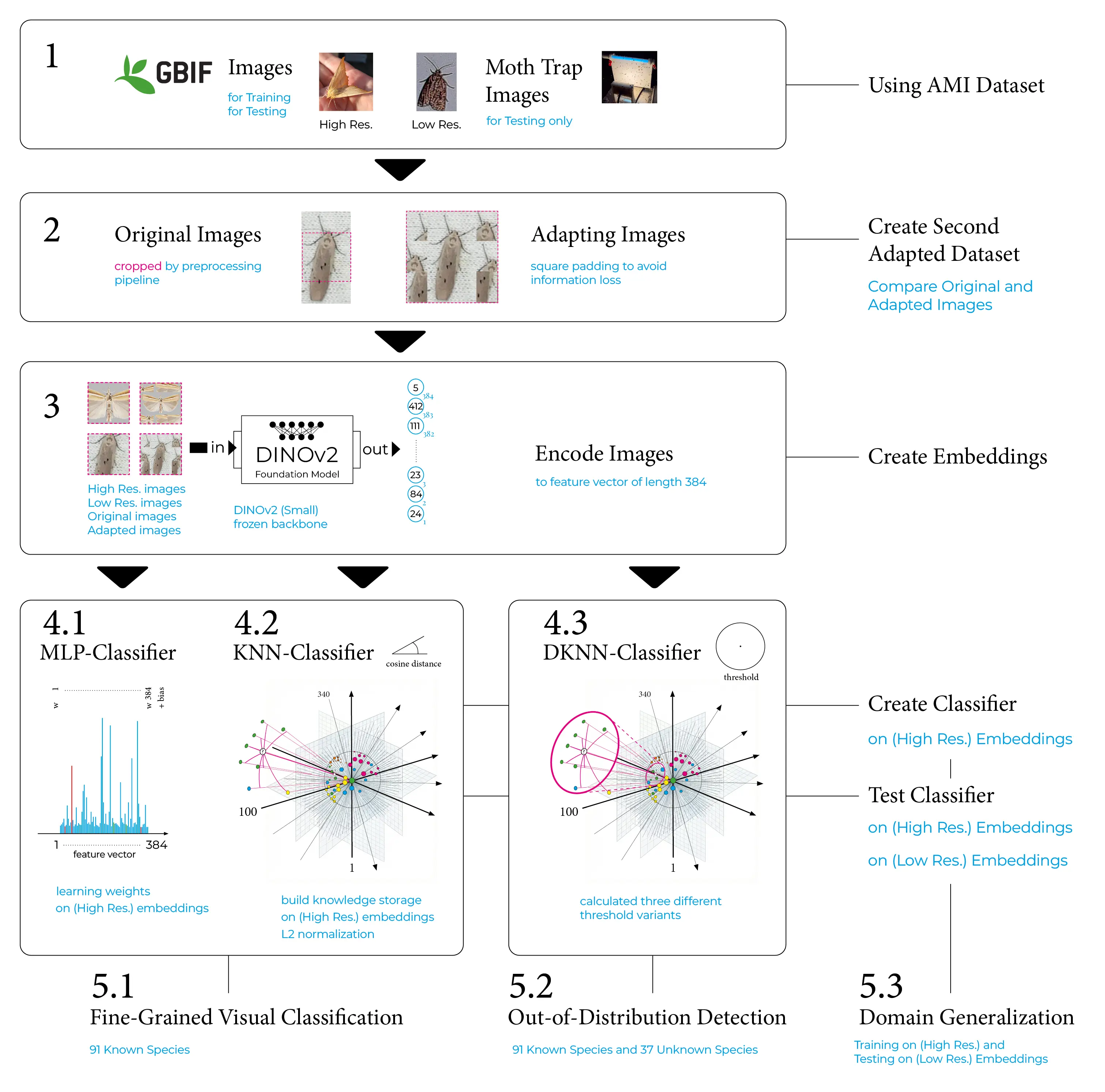
Autor: Johannes Leick, betreut von Jonas Alle
This thesis investigates the use of modern computer vision methods for automated moth monitoring in biodiversity research. Using self-supervised image embeddings extracted from the DINOv2 foundation model, the study evaluates approaches for fine-grained species classification, domain generalization, and novelty detection on the AMI dataset.
Several classifiers, including Multilayer Perceptron (MLP), K-Nearest Neighbor (KNN), and Deep K-Nearest Neighbor (DKNN), are evaluated across high-resolution GBIF imagery and low-resolution trap images representing real-world monitoring conditions.
Results show that the learned representations enable highly accurate fine-grained classification of 91 moth species on high-resolution images, achieving over 94% Balanced Accuracy. However, performance drops significantly under domain shift when models are applied to low-resolution trap imagery. Novelty detection experiments distinguishing 91 known species from 37 unseen species achieve moderate performance (AUROC of 0.65) on high-resolution data but degrade to near-chance levels under domain shift.
Additionally, a padded square dataset was introduced to reduce information loss during image encoding, showing degradation across all classifiers for high-resolution images, whereas a slight
improvement was observed for low-resolution images.
The results indicate that while DINOv2 embeddings effectively capture fine morphological differences in high-resolution latent space, maintaining class separability under low-resolution real-world images (domain shifts) remains a significant challenge.
Link to thesis(7.8 MB, 142 Seiten)
Link to code
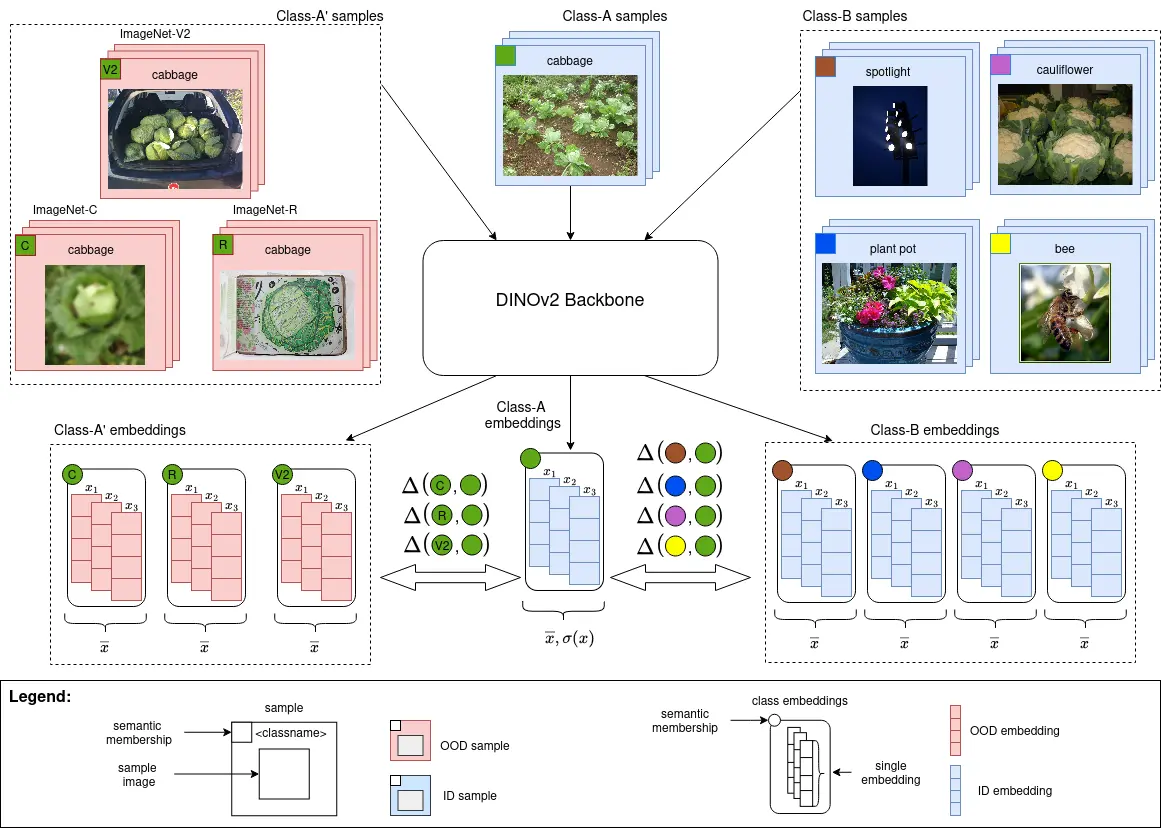
Autor: Alexander Fröhling, betreut von Jonas Alle
Vision Foundation Models (FMs) demonstrated convincing results regarding Out-of-Distribution (OOD) robustness. OOD cases are commonly encountered in real-world applications and often lead to performance degradation of traditional Machine Learning models. In contrast, the performance of vision FMs remains at an acceptable level under OOD conditions. Despite this advantage of vision FMs one drawback is their high complexity. Methods that interpret the behaviour of vision FMs are required for the responsible use of these models. In this regard, the objective of this thesis is to analyse the embedding space behaviour of the DINOv2 vision FM under covariate shift.
In the experiments, ImageNet-1k was used as In-Distribution (ID) dataset, while ImageNet-V2, ImageNet-R, and ImageNet-C served as OOD datasets. The focus of the thesis was to measure the change between the embeddings of OOD samples and ID samples that represent the same topic (i.e., sharing the same class label). For a qualitative evaluation, the measured changes induced by a covariate shift were compared to the changes measured between the embeddings of samples that originate from ImageNet-1k but represent different topics. Additionally, two logistic regression models were used to compute the accuracies for each OOD dataset and relate the changes measured in the embedding space to classification results.
For the ImageNet-V2 embeddings, a relatively small shift was observed, whereas for the ImageNet-R embeddings the shift was significantly larger. The ImageNet-C results revealed that, among all ImageNet-C corruption types, Brightness induced the smallest change in the embedding space, while Glass Blur resulted in the largest shift. The comparison of the measurement results in the embedding space with the classification results indicates that lower classification accuracy is associated with larger shifts in the embedding space. Furthermore, depending on the measure used to quantify changes in the embedding space, some differences were observed. The differences in the results may indicate that different types of covariate shift affect the embedding space in distinct ways, which are reflected differently by the respective measures.
Link to thesis(3.5 MB, 57 Seiten)
Link to code
Autor: Andreas Franz Schwab, betreut von Sebastian Dörrich
This thesis evaluates the applicability of modern real-time object detection algorithms for automated polyp detection in full-length clinical colonoscopy videos. Colonoscopy is a standard endoscopic procedure used for colorectal cancer screening and prevention, in which a flexible camera is advanced through the colon to visually inspect the mucosal surface for precancerous lesions (polyps). Automated detection in this setting is inherently challenging: polyps vary widely in size, shape, texture, and appearance, are often small or partially occluded, and can be difficult to distinguish from normal tissue even for experienced clinicians. In addition, colonoscopy videos frequently contain motion blur, specular highlights, fluids, debris, and strong illumination changes, while negative frames without lesions dominate full procedures.
While recent studies report high detection performance on curated image datasets or short video clips, these evaluation settings do not reflect real clinical conditions, where visual appearance varies strongly over time and true positives are sparse. As a result, reported performance often overestimates the effectiveness of computer-aided detection systems in practice. Using the recently released REAL-Colon dataset, which consists of complete, clinical-grade colonoscopy procedures with frame- and lesion-level annotations, this work establishes a standardized and reproducible evaluation framework for real-time polyp detection under realistic conditions.
Four representative detection architectures, namely Faster R-CNN, YOLOv8, YOLOv11, and RT-DETR, are systematically assessed using detection-level, frame-level, and lesion-level metrics to capture clinically relevant aspects such as false-positive behavior, temporal consistency, detection latency, and real-time suitability. The results show that detection performance drops substantially when models are evaluated on full procedures compared to curated benchmarks. Transformer-based models demonstrate higher sensitivity and temporal stability, whereas CNN-based detectors offer higher throughput and specificity. Additionally, models trained on full-procedure data generalize better to external datasets than those trained on curated clips. Importantly, the observed performance under realistic conditions remains insufficient for fully reliable clinical deployment, underscoring the need for more sophisticated modeling and evaluation approaches.
Link to thesis(4.3 MB, 92 Seiten)
Link to code

Autor: Hanh Huyen My Nguyen, betreut von Francesco Di Salvo
Deep learning holds great promise for advancing medical image analysis, but access to large and diverse datasets for robust training is often constrained by privacy regulations. Federated Learning (FL) enables collaborative training among distributed institutions without sharing raw data. However, conventional FL approaches, which rely on downstream model sharing, are restricted to specific tasks, incur high communication costs, and remain vulnerable to privacy attacks. We propose a novel FL framework that shifts from model-centric collaboration to privacy-preserving data sharing. By leveraging pre-trained foundation models (FMs), clients extract compact, semantically rich embeddings and share anonymized representations to support local downstream tasks without the need for parametric synchronization.
As anonymization strategies for this framework, we explore (i) a non-parametric approach based on unsupervised clustering and k-anonymity with additive differential privacy (DP) noise (DP-kSame), and (ii) a generative approach using a federated, differentially private Conditional Variational Autoencoder (DP-CVAE) to model a global, privacy-aware data distribution. Both methods enhance client autonomy and support personalized downstream learning with minimal additional training. Validated across multiple medical imaging datasets and feature extractors, our proposed methods outperform traditional FL classifiers while ensuring strong privacy guarantees. Together, they demonstrate the viability of FM-embedding-based data sharing for scalable and secure FL. DP-CVAE achieves the best privacy–utility trade-off, offering superior accuracy, fidelity, adaptability, and robustness against privacy attacks.
Link to thesis(2.7 MB)
Link to code
Link to paper

Autor: Marius Ludwig Bachmeier, betreut von Sebastian Dörrich
Biomedical imaging datasets are commonly difficult to access due to privacy constraints and frequently suffer from limited sample quality and quantity. Moreover, modern deep learning models experience a decline in classification performance when generalizing across domains, as compared to domain-specialized models. This thesis addresses the challenge of generalization across biomedical domains, analyzing the performance of domain-specific state-of-the art models compared to models trained for cross-domain generalization.
MedMNIST+ represents a diverse collection of biomedical imaging datasets, encompassing multiple classification tasks and resolutions across different domains. Existing image classification benchmarks in the biomedical domain are scarce, fall short in evaluating cross-domain generalization and neglect considering variations in image resolution. To address this shortfall, a benchmark is detailed in this thesis that captures a range of performance metrics tailored to evaluate model performance on multi-domain biomedical classification problems. This benchmark makes it possible to compare results in a standardized manner with evaluation metrics specifically suited for evaluation cross-domain generalization.
Furthermore, a prototype website is developed to host a leaderboard system for the proposed benchmark. This website aims to facilitate reproducible evaluation and standardized comparison of results. The website automates model evaluation, making it possible for researchers to submit and benchmark their models against baseline models.
Within the scope of this thesis, a reevaluation of existing models is performed in order to account for their generalization capabilities. In particular, the benchmark metrics are computed for existing domain-specific models, allowing a comparison against cross-domain generalization models.
Both a Convolutional Neural Network as well as a Vision Transformer model were trained using a multi-domain, multi-task training paradigm to gather this data. This training paradigm employs a shared backbone connected to different classification heads. Evaluating these multi-domain models represents an investigation of how shared feature representations can be used to perform classification.
Ultimately, the multi-domain Vision Transformer model largely performed competitively as compared to domain-specific models but didn’t match the best performing domain-specific models. These findings highlight the potential of multi-domain multi-task training for cross-domain generalization in biomedical image classification, underscoring how future research aimed at modifying the multi-domain, multi-task training paradigm or performing hyperparameter optimization might improve the performance of multi-domain models to match the performance of domain-specific models.
Link to thesis(4.9 MB, 78 Seiten)
Linke to code

Autor: Hilke Maria Ahlers, betreut von Francesco Di Salvo
This thesis investigates test-time augmentation for domain generalization in image classification, asking whether injecting source-domain feature statistics at inference improves robustness and at which network depths it works best. Using a ResNet-50 backbone and the LODO Evaluation set up on PACS and VLCS, the method stores per-domain channel-wise means and standard deviations from all convolutional layers and, at test time, replaces a sample’s latent style statistics with those from source domains. Multiple insertion modes are compared against a training baseline trained with the data augmentation approach MixStyle.
Results show a clear depth effect and dataset dependence. On PACS, where shifts are largely stylistic, shallow/mid-layer interventions improve or match baseline accuracy, with the Sketch domain benefiting most. Deep-layer and averaging adaptations collapse performance. On a dataset with more semantic oriented shifts such as VLCS, augmentation at test-time rarely surpasses MixStyle and deeper interventions remain harmful. Directionality matters, where the best source style is often a complementary domain.
The work also introduces per-sample prediction variance across style augmentations as an uncertainty signal. On PACS it strongly predicts errors and enables effective selective prediction; on VLCS it is moderately useful and domain-dependent. Limitations include architectural coupling to ResNet hooks, heuristic aggregation, and overheads for runtime and storage.
Overall, test-time style-statistics injection is effective when domain shifts are stylistic and the intervention remains shallow; it is ill-suited for semantic shifts. The findings clarify when test-time augmentation complements training-time Domain generalization and motivate adaptive, depth-aware, and dataset-aware deployment.
Link to thesis(20.2 MB)
Link to code

Autor: Florian Gutbier, betreut von Sebastian Dörrich
Image classifiers often display significant performance drops when confronted with images that differ in some way from their training data. This thesis addresses the problem of out-of-distribution (OOD) robustness by introducing an open-source Unreal Engine 5 plugin for the generation of fully controllable, photorealistic datasets for systematic stress-testing of vision models.
The developed plugin allows to vary a combination of six different generative factors: background, material, lighting, camera pose, fog, and object identity, directly within UE5 without external tools. Using this framework, a synthetic benchmark of 86,016 images across seven ImageNet classes was created. Each image is accompanied by precise metadata, enabling fine-grained analysis of model behaviour under distribution shifts.
Evaluations of convolutional and transformer-based architectures (including ResNet, ConvNeXt, ViT, and Swin) reveal significant performance drops under combined shifts, with the best model only achieving a Top-1 accuracy of 37.5 % when evaluated against the whole dataset. Analysis shows that changes in material or viewpoint can reduce accuracy by more than 30 percentage points, while volumetric fog sometimes improves recognition by simplifying backgrounds.
By releasing both the plugin and dataset under an open-source license, this work provides a reproducible and extendable pipeline for studying model robustness and a practical tool for generating semantically structured synthetic data in computer vision research.
Link to thesis(13.0 MB)
Link to code
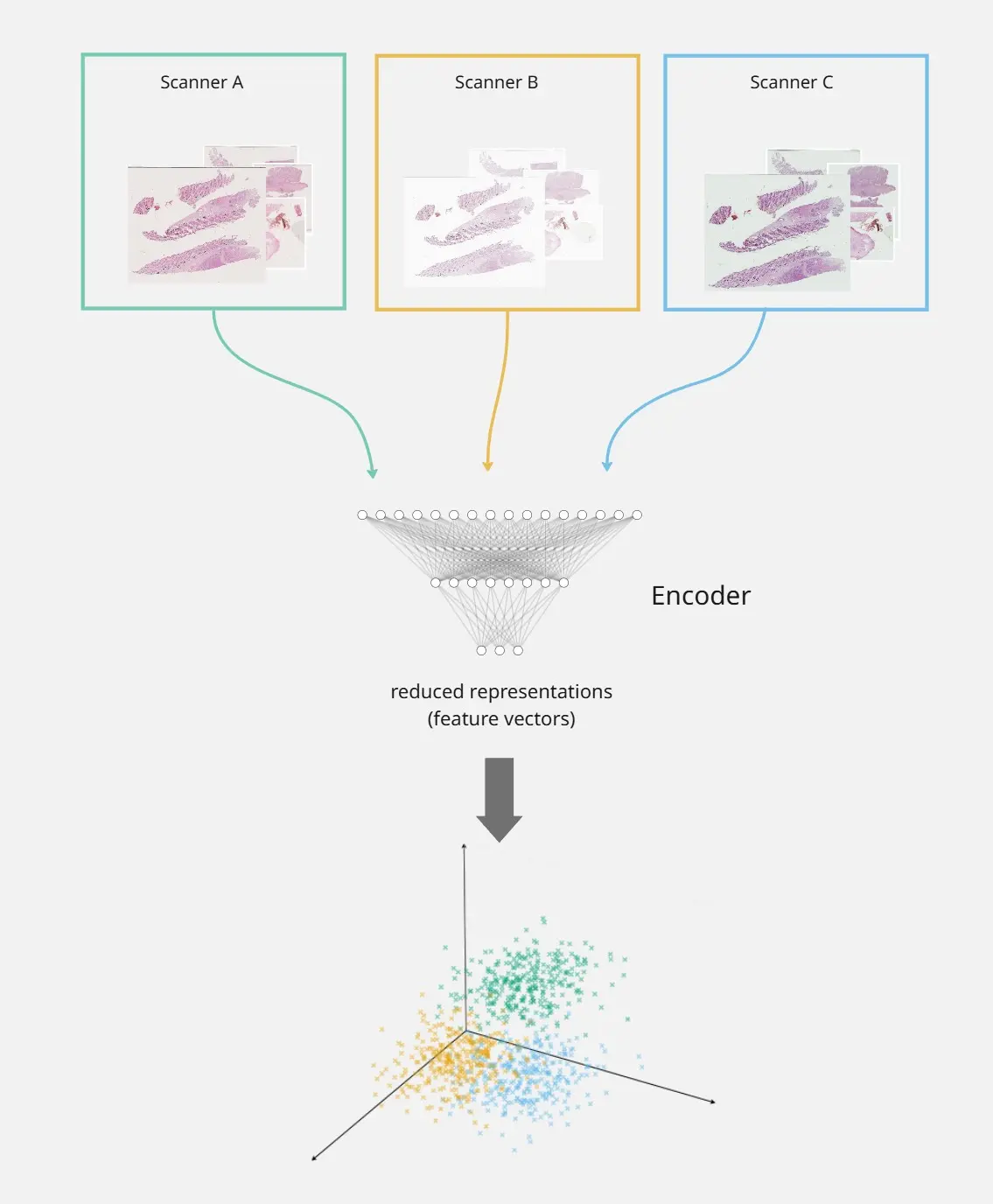
Autor: Kian Fried Hinke, betreut von Sebastian Dörrich
One of the main challenges in applying machine learning to medical imaging is domain shift, where models trained on one type of data perform differently when faced with new data. This thesis looks specifically at scanner-induced domain shift, which occurs when the same tissue sample is digitised using different scanners. Even small variations in image acquisition can have a strong impact on model performance.
To study this effect, a dataset of 44 histopathology samples scanned on five different devices was used. Three approaches were compared:
● BBSD, which looks at the output distributions of classifiers,
● MMD, which measures distances between feature representations, and
● PAD* in a multi-class setting, which learns to distinguish between scanners.
These methods were tested on different types of models, ranging from simple neural networks to a fine-tuned ResNet18 and pretrained foundation models such as DINO and DINOv2.
The results show that task-specific methods like BBSD and PAD* provide useful indicators of how domain shift affects performance, while task-agnostic methods like MMD may detect differences that are not always relevant for the task at hand. ResNet18 proved relatively robust across scanners, while foundation models needed fine-tuning to capture task-relevant features, which raises questions about their direct use in histopathology.
Overall, the work highlights that scanner-induced domain shift cannot be measured in isolation. The methods studied are best seen as lightweight and complementary tools that help interpret and anticipate domain shift, rather than as definitive measures.
Link to thesis(16.9 MB)
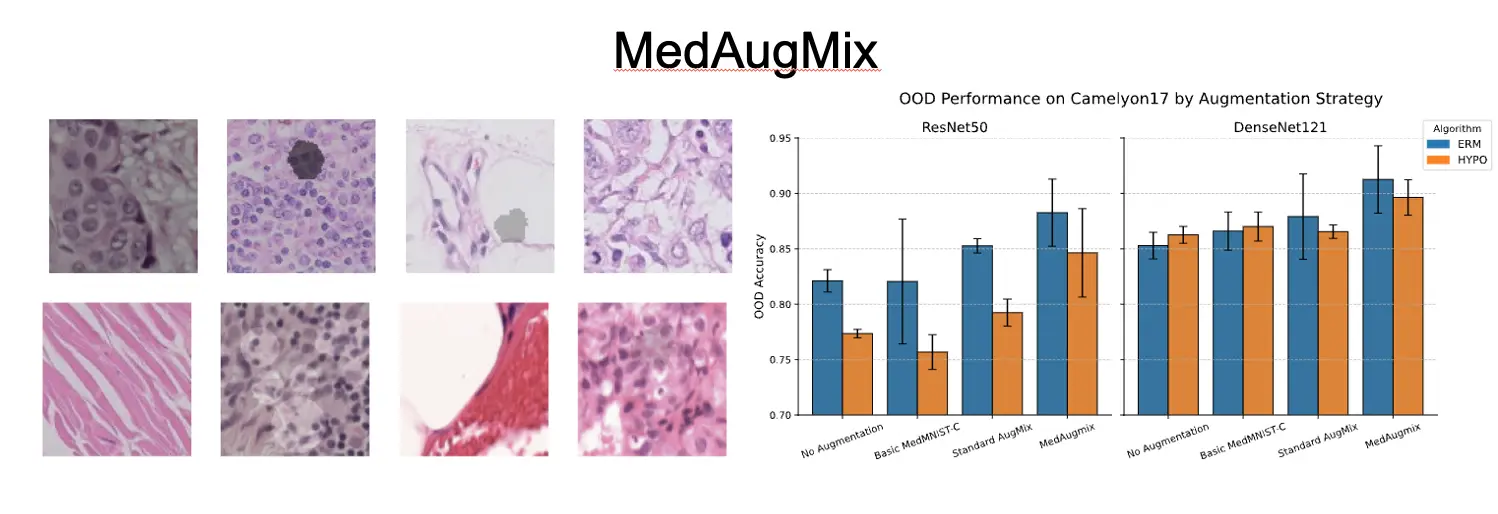
Autor: Muhammad Tayyab Sheikh, betreut von Francesco Di Salvo
The clinical translation of deep learning models in medical imaging is critically limited by their failure to generalize to out-of-distribution (OOD) data. Models trained in one clinical setting often underperform when encountering variations in patient populations, imaging equipment, and preparation protocols. This thesis addresses this challenge by systematically benchmarking strategies to improve OOD generalization across two distinct medical domains: inter-hospital variability in histopathology, using the WILDS Camelyon17 dataset, and skin tone bias in dermatology, using the Fitzpatrick17k dataset.
Our evaluation benchmarks two fundamental approaches against the standard training method, Empirical Risk Minimization (ERM). The first approach to be tested is a specialized algorithmic approach, HYPO, a representation learning strategy that seeks to learn domain-invariant features by actively organizing them on a hypersphere. Its goal is to make features from the same class cluster tightly together regardless of their source domain, while pushing clusters of different classes far apart.
The second approach is data-centric, for which we evaluate multiple augmentation strategies. This includes leveraging AugMix, a powerful processing framework that creates diverse training examples by mixing multiple augmentation chains, and MedMNIST-C, a benchmark providing targeted corruptions that simulate realistic medical image artifacts. This culminates in our proposed novel method, MedAugmix, which combines these ideas by using the targeted corruptions from MedMNIST-C as the core ingredients within the robust AugMix framework.
Our findings reveal a clear hierarchy of effectiveness. While the HYPO algorithm provides a solid improvement over the baseline, confirming the value of representation learning, the most significant performance gains were achieved through our data-centric approach. The proposed MedAugmix strategy delivered the most substantial gains, drastically reducing the OOD performance gap. For example, on the challenging Camelyon17 benchmark, ERM with MedAugmix achieved an OOD accuracy of 0.913 compared to 0.853 for standard ERM—a substantial 6.0 percentage point improvement that exceeded all evaluated HYPO configurations. Crucially, a standard ERM model, when enhanced with MedAugmix, consistently outperformed the specialized HYPO algorithm across both the histopathology and dermatology benchmarks, demonstrating the generalizability of this core finding.
This thesis concludes that while specialized OOD algorithms are beneficial, a sophisticated, data-centric approach focused on targeted augmentation can be even more impactful for building robust medical AI. The success of the proposed MedAugmix strategy highlights that focusing on high-quality data augmentation that simulates realistic domain shifts is a crucial and highly effective path toward developing models that are not only accurate but also equitable and reliable enough for real-world clinical deployment.
Link to thesis(8.3 MB)
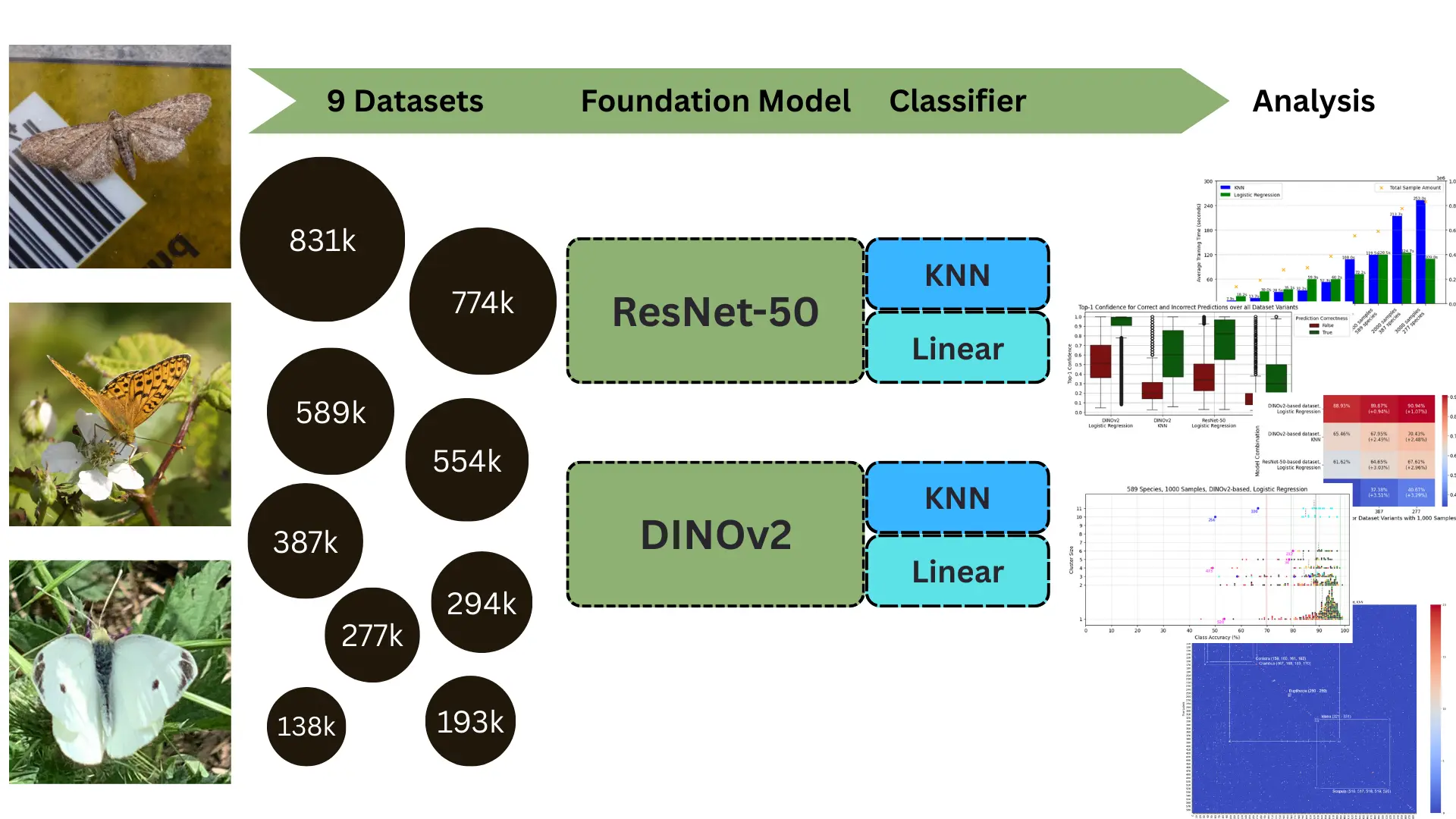
Autor: Leopold Gierz, betreut von Jonas Alle
Citizen science initiatives pose a great opportunity to benefit biodiversity research by enabling the collection of vast observational datasets. In this work, a 1.39 million-image butterfly dataset from the citizen science initiative Observation.org was experimented with in its unfiltered form, thus preserving the natural variation in quality typical of citizen-generated data. To evaluate how dataset composition affects fine-grained classification, nine dataset variants were created by varying species counts (277 to 589 species) and sample amounts (500 to 3,000 images per species).
Feature embeddings were then extracted from two foundation models — DINOv2-Giant and ResNet-50 — and used to train both Logistic Regression (a linear classifier) and K-Nearest Neighbors classifiers. Cross-validation was employed throughout to ensure reliable performance estimates. Consequently, DINOv2-based embeddings outperformed those from ResNet-50: the highest top-1 accuracy, 92.78%, was achieved by pairing DINOv2 with Logistic Regression on the dataset variant containing 277 species with 3,000 samples each. In contrast, ResNet-50 with identical configurations peaked at only 70.34%. Notably, even under the most challenging variant (589 species, 500 samples each), DINOv2 maintained strong accuracy (86.77%), whereas ResNet-50 dropped to 57.81%. Meanwhile, Logistic Regression generally surpassed KNN by roughly 20 to 25 percent in top-1 accuracy on all dataset variants.
Furthermore, this work investigates the impact of higher taxa and visual similarities between species on classification performance under varying dataset configurations.
The findings demonstrate that uncurated citizen-science data, when coupled with modern foundation models, can yield high-precision classification results. Ultimately, this approach offers a scalable framework for ecological monitoring and conservation, indicating that even modest sampling efforts can yield robust biodiversity insights.
Link to thesis(8.3 MB)
Link to code
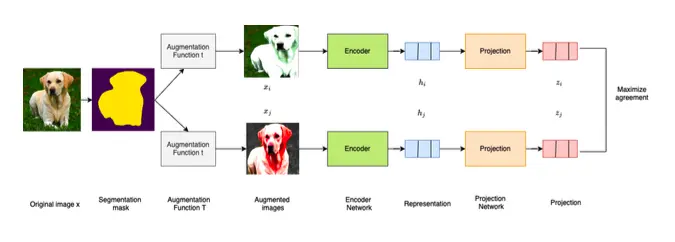
Autor: Sascha Wolf, betreut von Jonas Alle
This thesis explores enhancements to the SimCLR framework, a prominent method in self-supervised contrastive learning. The core contribution is SegAug-SimCLR, a segmentation-based augmentation pipeline that leverages semantic image segmentation to apply targeted data augmentations. Using DeepLabV3, images are split into foreground and background, enabling region-specific transformations. This method preserves object details while increasing training data variability. Experiments on ImageNet (pretrained on 10% training data) show a modest Top-1 accuracy improvement of 0.6%. Transfer learning on datasets like Oxford Flowers yields taskdependent gains (+1.0%). However, the eVects of segmentation-based augmentations on full ImageNet pretraining remain an open area for future research.
Link to thesis(2.7 MB)
Link to code
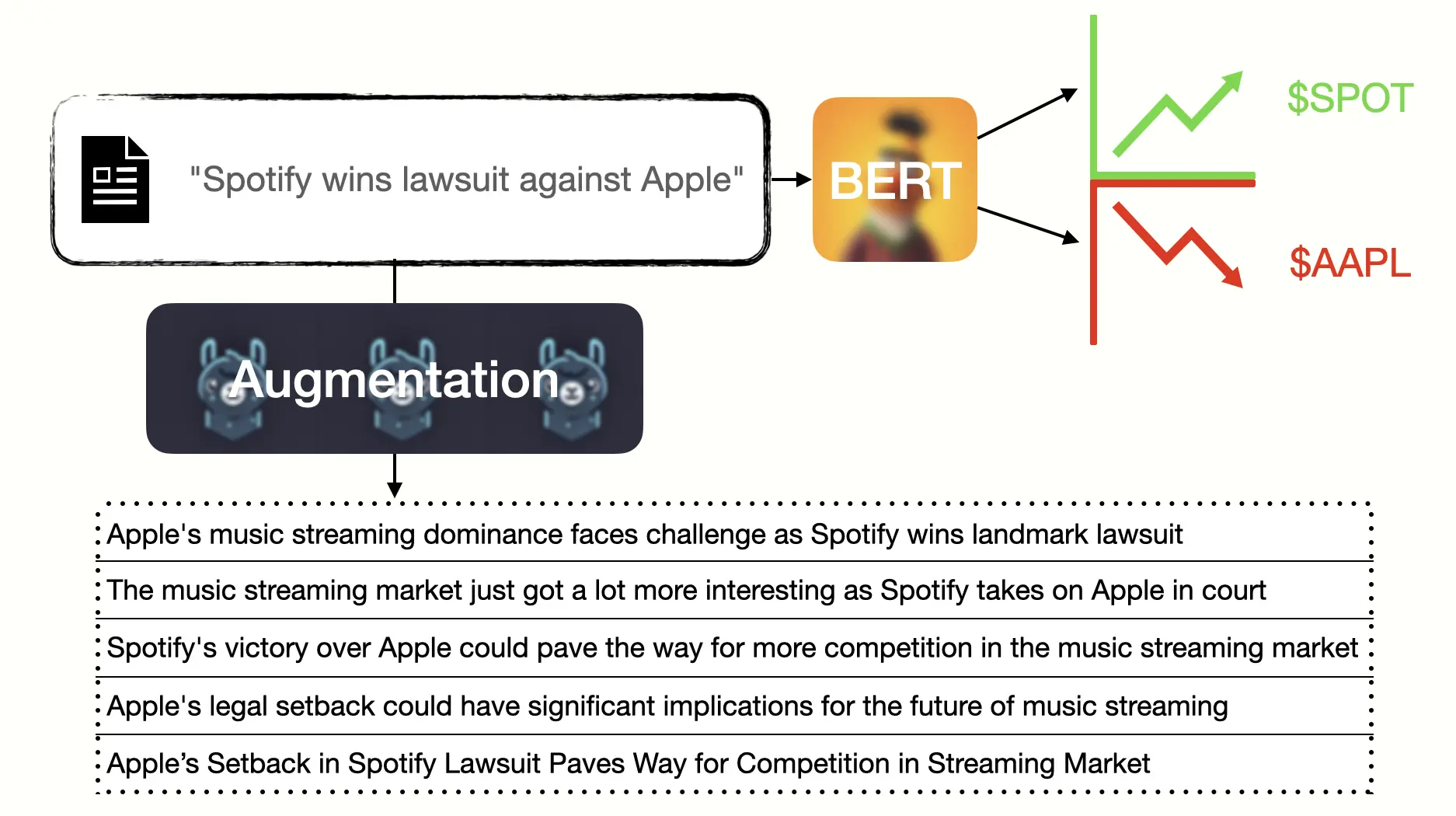
Autor: Pascal Cezanne, betreut von Sebastian Dörrich
This thesis explores the challenge of predicting stock price movements based on financial news, addressing the gap between textual sentiment and actual market reactions. Traditional sentiment analysis fails in this context, as positive or negative sentiment does not directly translate to bullish or bearish market movements. To tackle this issue, a dataset was created, linking financial news titles to historical price data using Rate of Return and Excess Return as target variables. This approach isolates external market factors, enabling market sentiment predictions.
To counteract the inherent class imbalance in financial datasets, various textual data augmentation techniques were evaluated, including advanced LLM-assisted methods. These techniques proved essential in mitigating overfitting, ensuring model robustness. The research further demonstrated that pre-trained sentiment models like FinBERT are ineffective for market predictions, necessitating training with price-based target data.
Experimental results showed that the developed model performs comparably to other machine learning-assisted trading strategies. While challenges remain in fully capturing the complexities of financial markets, this work provides with its dataset a foundation for future research into stock-aware sentiment analysis and market prediction models.
However, the thesis does not delve into training a model that explicitly makes stock-aware predictions, making this a subject for future research.
Link to thesis(8.8 MB)
Link to code
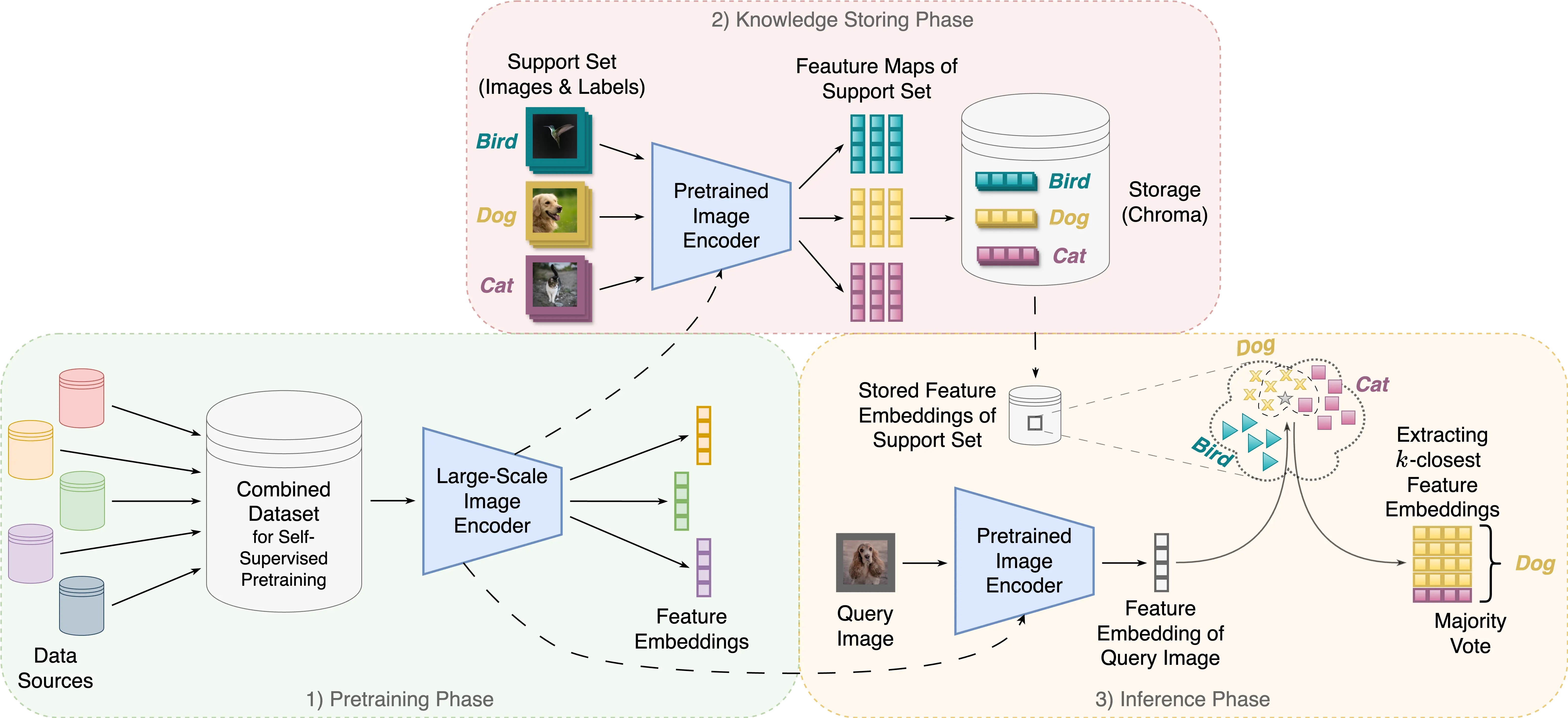
Autor: Tobias Archut, betreut von Sebastian Dörrich
This thesis explores the challenge of continual learning and data privacy in image classification and presents an explainable k-NN-based approach as a solution. Traditional deep learning models struggle with adapting to new data or removing existing data due to their inherent structure where knowledge is stored within model weights. This inflexibility poses a problem for data privacy, especially with regulations like GDPR that empower users to request the deletion of their data. The proposed method tackles these issues by combining pre-trained image encoders, ResNet and Vision Transformer (ViT), with the k-NN algorithm.
The process involves:
- Supervised Feature Embedding: The pre-trained ResNet or ViT model extracts features from images in the support set to create embeddings. These embeddings, along with corresponding labels, are stored in an external database, Chroma.
- Classification of New Image: When a new image needs to be classified, the same pre-trained model extracts its features and generates an embedding.
- k-NN for Classification: The new image's embedding is compared to the stored embeddings in Chroma. The k-nearest neighbors, determined using a distance metric like cosine similarity, are identified.
- Classification: A majority vote on the labels of these k-nearest neighbors determines the classification of the new image.
This approach offers several benefits:
- Continual Learning: New data (classes or samples) can be seamlessly added to the database without retraining the entire model. This facilitates continual learning and mitigates catastrophic forgetting, a common issue in traditional models.
- Data Privacy: Data can be easily removed from the database to comply with user requests, without requiring computationally expensive model retraining.
- Explainability: The decision-making process is transparent. The k-nearest neighbors and their similarity score to the query image can be visualized to explain the classification.
- Cost-Effective: The approach leverages pre-trained models, eliminating the need for resource-intensive training from scratch.
The thesis evaluated the performance of this k-NN approach across a range of datasets, including CIFAR-10, CIFAR-100, STL-10, Pneumonia, and Melanoma. Experiments explored the impact of different hyperparameters, including the value of 'k' in the k-NN algorithm. Additionally, different dimensionality reduction techniques were assessed to visualize and explain the decision process of the proposed approach. The research showcases the efficacy of the k-NN approach. For instance, the approach achieves accuracies of 98.5% on CIFAR-10, 88.3% on CIFAR-100, and 99.5% on STL-10, demonstrating strong performance on natural image datasets. It also performs well on medical image datasets, achieving 89.9% accuracy on Pneumonia and 69.8% on Melanoma. Notably, these results on medical datasets are comparable to, and in some cases even exceed, the performance of fully supervised state-of-the-art models, highlighting the transfer learning capabilities of the approach. The thesis aims to demonstrate that this k-NN-based approach is a viable and advantageous alternative to traditional deep learning models for image classification. It presents a compelling case for a more adaptable, privacy-aware, explainable, and cost-effective solution.
Link to thesis(18.9 MB)
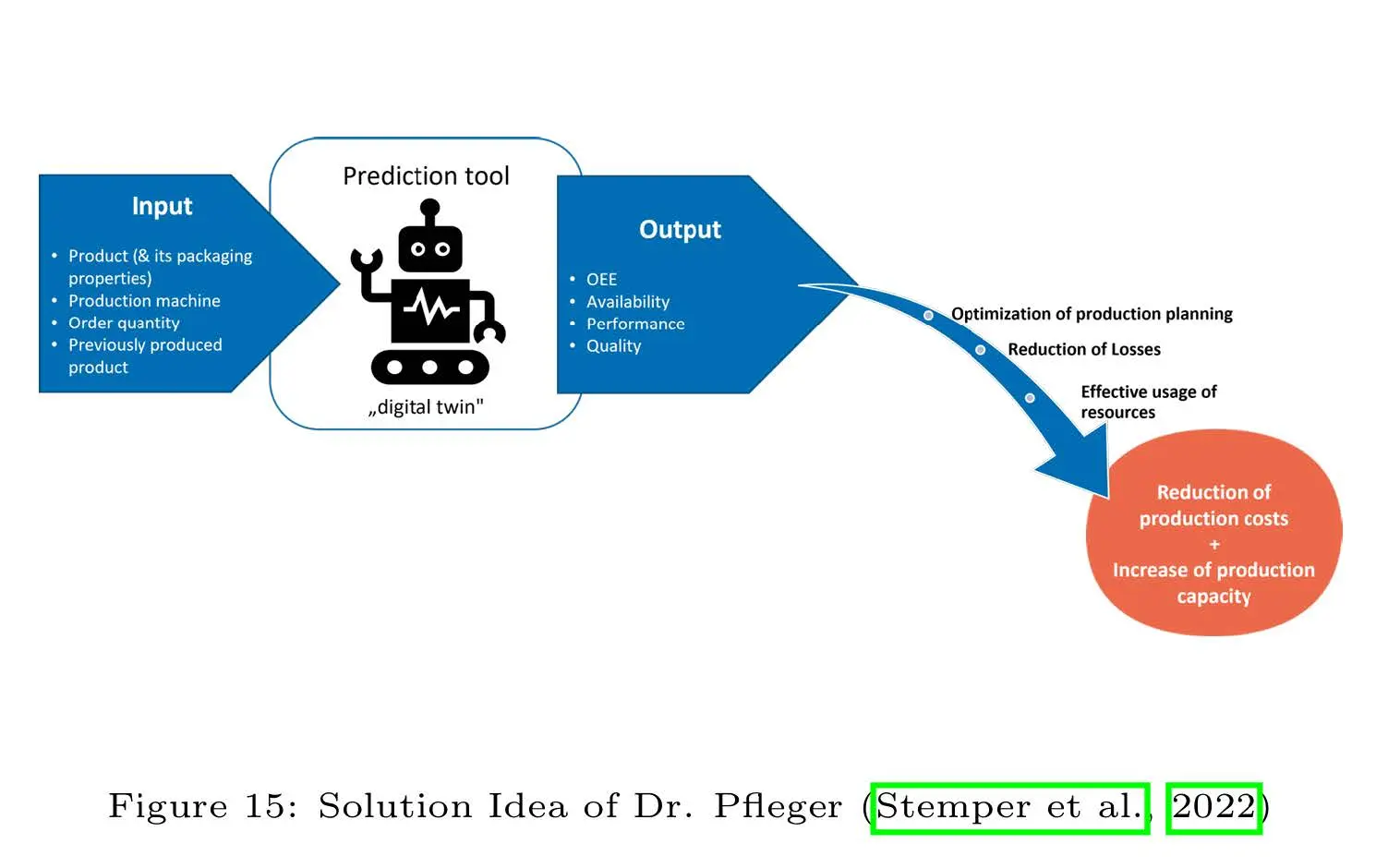
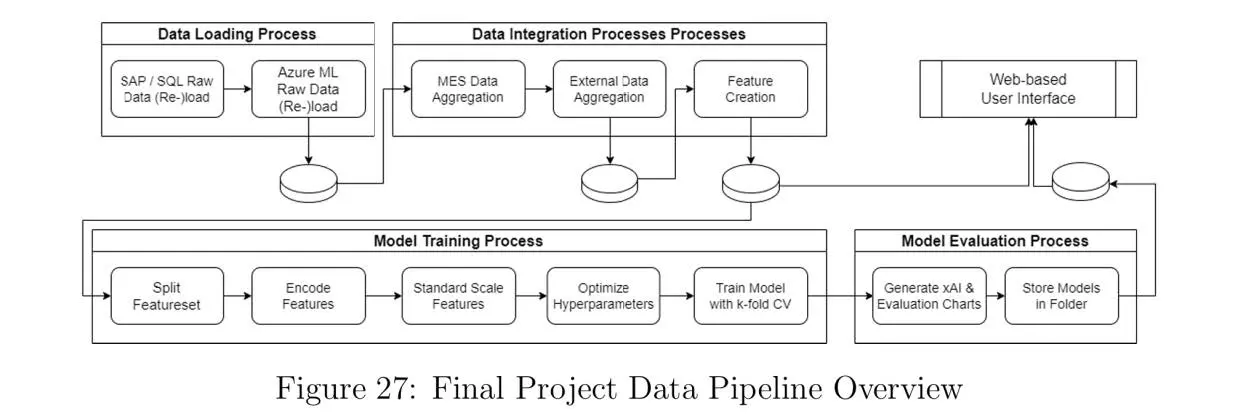
Autor: Nicolai Frosch, betreut von Christian Ledig
The thesis investigates the use of data-driven machine learning (ML) techniques to improve production planning and enhance Overall Equipment Effectiveness (OEE) in the pharmaceutical manufacturing industry, conducted in collaboration with Dr. Pfleger Arzneimittel GmbH. The study investigates the OEE, which measures key challenges in production scheduling, including machine downtime, suboptimal performance, and quality inefficiencies.
Through a structured methodology rooted in action research and Design Science Research (DSR), the project incorporates data integration, feature engineering, model training, and hyperparameter optimization to predict OEE and other Key Performance Indicators (KPIs). Ten different ML-algorithms were evaluated, with ensemble methods emerging as top performers in predicting the OEE. To ensure stakeholder trust and transparency, the models were investigated with SHAP values. While implementing the ML-algorithms this thesis phased classical challenge of practical projects, like limited data availability, bad data quality and changing project goals during the implementation period.
The research outcomes include a functional prototype of a web-based user interface that integrates trained ML models to support human planners in generating optimized production schedules. The interface enables planners to simulate production scenarios, visualize scheduling proposals, and make informed decisions to reduce downtime and operational losses. Although fully autonomous scheduling was beyond the project's scope, the thesis demonstrates the potential of ML-driven decision-support systems in achieving incremental efficiency gains and minimizing production losses.
This work underscores the feasibility of using machine learning to predict KPIs and improve production planning, showing in a practical setting how ML can be used in smart manufacturing. It provides a foundation for future developments toward autonomous scheduling and increased operational excellence in the manufacturing domain.
Link to thesis(9.9 MB)

Autor: Junquan Pan, betreut von Christian Ledig
This thesis presents an AI-based system for the automated detection of wood knots in historic timber structures, designed to support heritage conservation efforts. Traditional manual methods for assessing the condition of timber structures are often inefficient, error-prone and unsuitable for challenging environments. By integrating advanced machine learning and deep learning technologies, such as Detectron2 and YOLOv8, this work introduces a robust and systematic workflow to improve the accuracy and efficiency of timber defect analysis.
The research involves two main stages: segmentation to identify wood surfaces, and detection to locate and analyse wood knots. High-resolution datasets were meticulously collected from heritage sites, including the Dominican Church in Bamberg, as well as timber workshops, to ensure diverse and high-quality training data. These datasets were used to train and validate the proposed models, overcoming challenges such as varying lighting conditions, irregular wood textures and knot complexity.
The system not only facilitates accurate assessment of wood condition, but also contributes to the conservation of historic resources by minimising unnecessary material replacement. The ultimate goal is to provide conservators with a mobile application that integrates these AI-driven tools, enabling efficient and detailed in-situ analysis of wooden structures. This work highlights the transformative potential of AI in heritage conservation, bridging the gap between traditional techniques and modern computational methods.
Link to thesis(14.3 MB)
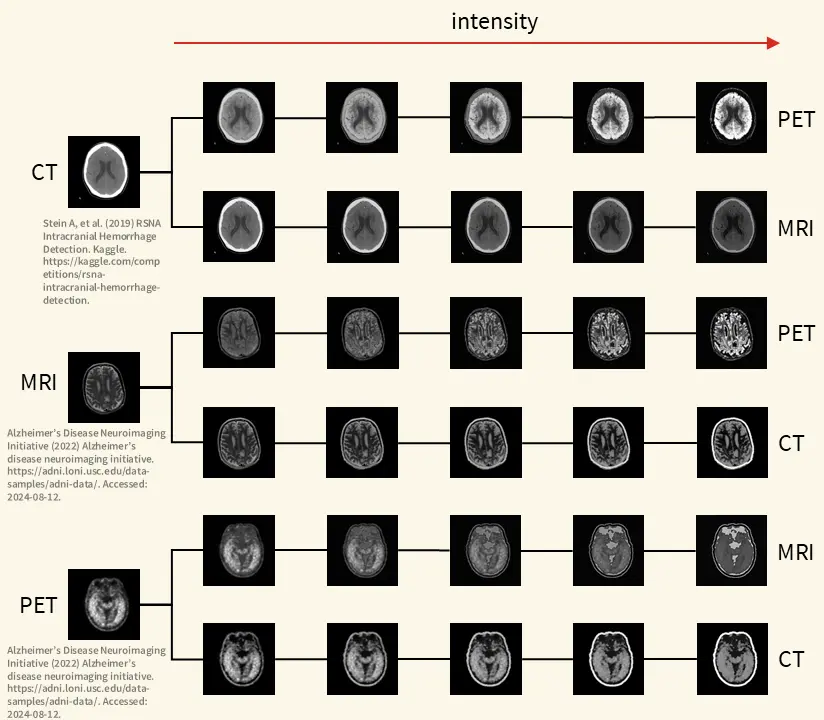
Autor: Julius Stutz, betreut von Sebastian Dörrich
This thesis explores the challenge of data scarcity in medical imaging for deep learning applications and presents the Cross-Modality Data Augmentation (CMDA) as a new approach. Medical imaging data is limited due to privacy concerns, ethical restrictions, and technical constraints, which makes model development substantially harder in this domain. CMDA addresses these challenges by translating images between modalities (medical imaging techniques) such as PET, MRI, and CT to enhance dataset diversity and improve model robustness.
CMDA consists of four augmentations tailored to modality-specific characteristics: color, artifacts, spatial resolution, and noise. It allows to adjust its settings appropriately for each use-case and integrates seamlessly into existing data augmentation pipelines. The method aims to synthesize new training samples that visually align with the target modality, potentially improving generalization in neural networks.
The approach was evaluated through quantitative experiments, comparing classification performance of models trained with CMDA and other augmentations. Results showed marginal improvements in some cases but noticeable performance drops in others. Qualitative experiments, however, demonstrated CMDA’s success in aligning images to target modalities, with two experiments showing an average alignment improvement of 23.5%.
Despite limitations in model generalization and robustness, CMDA demonstrates its potential in addressing cross-modality challenges, offering a foundation for future research in medical data augmentation and image translation.
Link to thesis(18.7 MB)
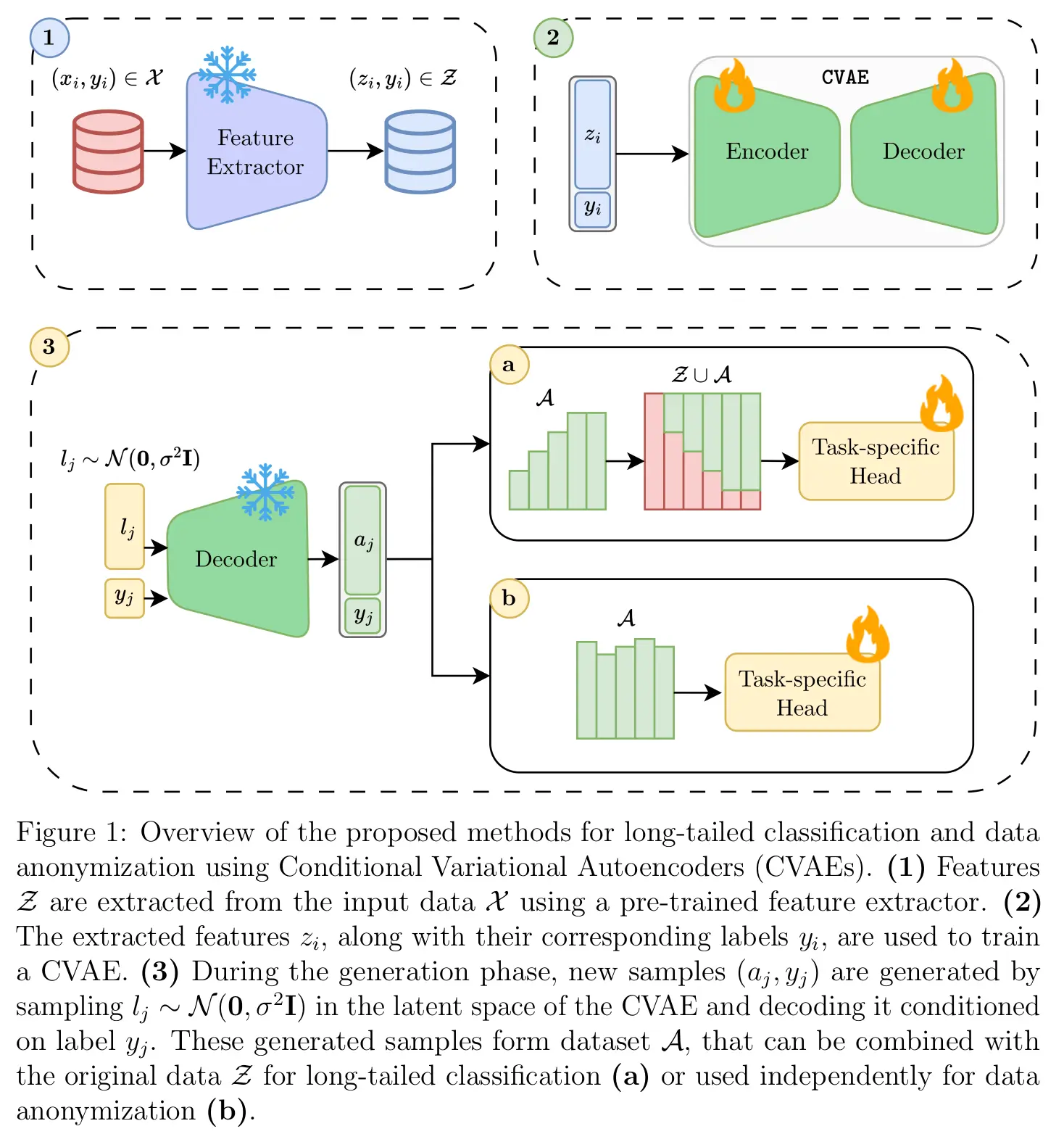
Autor: David Elias Tafler, betreut von Francesco Di Salvo
This thesis explores the potential of generative data augmentation in the embedding space of vision foundation models, aiming to address the challenges of long-tailed learning and privacy constraints. Our work leverages Conditional Variational Autoencoders (CVAEs) to enrich the representation space for underrepresented classes in highly imbalanced datasets and to enhance data privacy without compromising utility. We develop and assess methods that generate synthetic data embeddings conditioned on class labels, which both mimic the distribution of original data for privacy purposes and augment data for tail classes to balance datasets. Our methodology shows that embedding-based augmentation can effectively improve classification accuracy in long-tailed scenarios by increasing the diversity and volume of minor class samples. Additionally, we demonstrate that our approach can generate data that maintains privacy through effective anonymization of embeddings. The outcomes suggest that generative augmentation in embedding spaces of foundation models offers a promising avenue for enhancing model robustness and data security in practical applications. The findings have significant implications for deploying machine learning models in sensitive domains, where data imbalance and privacy are critical concerns.
Link to thesis(8.8 MB)

Autor: Peiyao Mao, betreut von Francesco Di Salvo
This thesis investigates the efficacy of deep hashing methods applied to image embeddings derived from state-of-the-art Vision Transformer (ViT) models, focusing on both the semantic preservation be tween original image embeddings and hashed image embeddings and the strengthening of data privacy. The contribution of the experiment involves the transformation of image embeddings to hashed image embeddings using various deep supervised hashing methods, making sure the semantic similarities are preserved, and data privacy is enhanced. We innovatively apply Triplet Center Loss (TCL) in the domain of deep hashing, aiming to achieve both high performance and computational efficiency. By comparing various deep supervised hashing methods, including pairwise and triplet methods, the experiment try to understand and evaluate how different approaches perform under the same conditions. It provides insights into which methods are most effective in retaining important data characteristics after hashing. A key aspect of this research is the emphasis on privacy preservation. By converting raw image data into hashed forms, this work explores how advanced hashing techniques can obscure original data features, thereby enhancing privacy without substantially compromising the utility for tasks such as medical image retrieval. This dual focus addresses the critical challenge of using sensitive image data in environments where privacy concerns are important.
Link to thesis(2.7 MB)

Autor: Jonida Mukaj, betreut von Ines Rieger
This thesis explores the application of feature visualisations on medical datasets, specifically for skin cancer imaging, using pre-trained convolutional neural networks like AlexNet, VGG16, and ResNet50 to enhance model interpretability, and fine-tuning those models to the ISIC benchmark dataset. Comparative analysis of ISIC 2019 and 2020 datasets shows varying model strengths, with VGG16 leading in accuracy and ResNet50 generalizability. Feature visualizations reveal diagnostic patterns in skin cancer, aiding in understanding network decision-making, yet pose challenges in medical interpretation. The study underscores the importance of deep learning in medical imaging and suggests combining feature visualizations with other interpretability techniques for future advancements.
Link to thesis(17.2 MB)

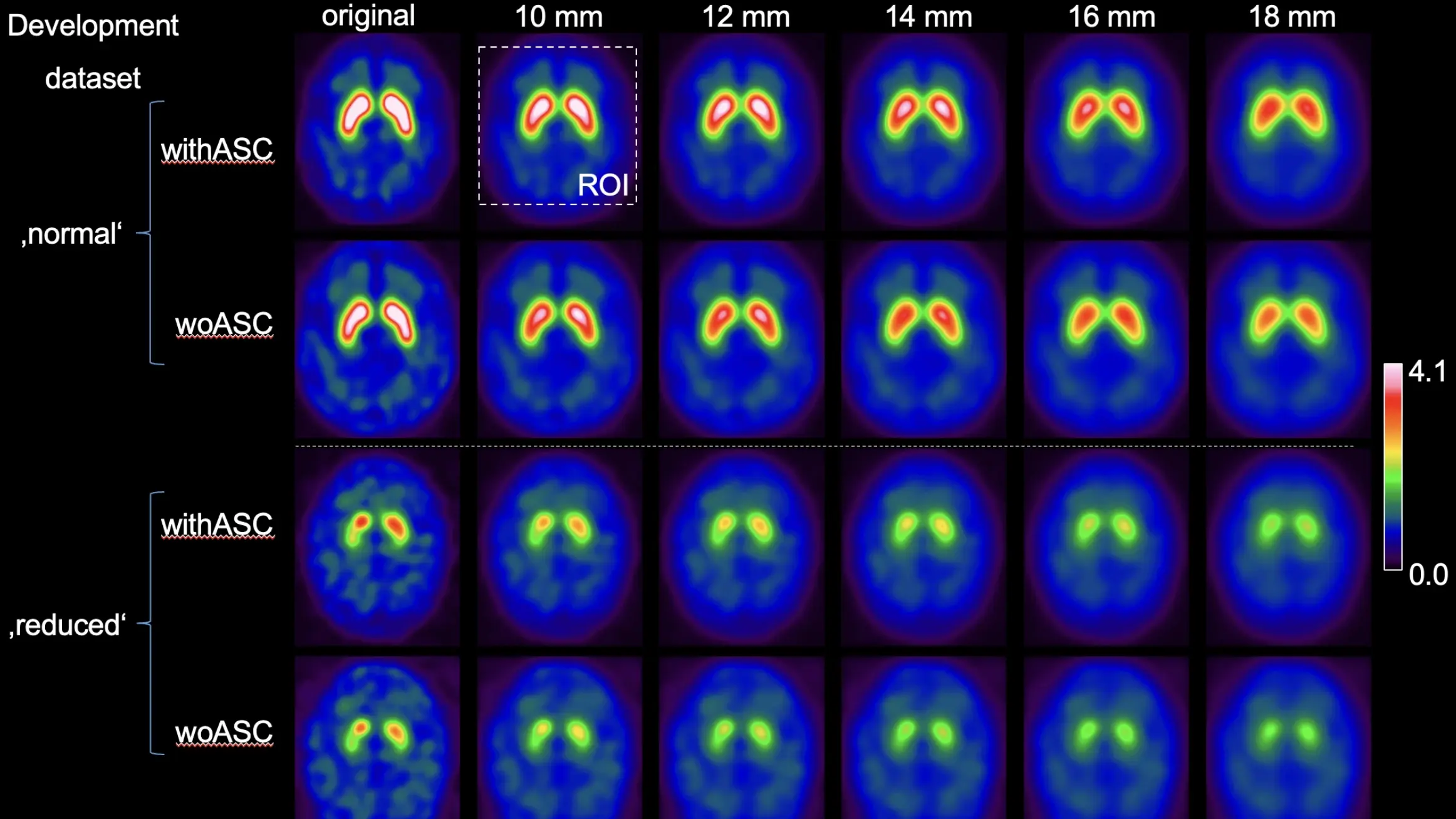
Autor: Aleksej Kucerenko, betreut von Prof. Dr. Christian Ledig and Dr. Ralph Buchert
Parkinson's disease (PD) is a prevalent neurodegenerative condition posing significant challenges to individuals and societies alike.
It is anticipated to become a growing burden on healthcare systems as populations age.
The differentiation between PD and secondary parkinsonian syndromes (PS) is crucial for effective treatment, yet it remains challenging,
particularly in cases of clinically uncertain parkinsonian syndromes (CUPS).
Dopamine transporter single-photon emission computed tomography (DAT-SPECT) is a widely used diagnostic tool for PD,
offering high accuracy but also presenting interpretational challenges, especially in borderline cases.
This study aims to develop reliable automated classification methods for DAT-SPECT images, particularly targeting inconclusive cases,
which may be misclassified by conventional approaches.
Convolutional neural networks (CNNs) are investigated as promising tools for this task.
The study proposes a novel performance metric, the area under balanced accuracy (AUC-bACC) over the percentage of inconclusive cases,
to compare the performance of CNN-based methods with benchmark approaches (SBR and Random Forest).
A key focus is the training label selection strategy, comparing majority vote training (MVT) with random label training (RLT),
which aims to expose the model to the uncertainty inherent in borderline cases.
The study evaluates the methods on internal and external testing datasets to assess generalizability and robustness.
The research was conducted in collaboration with the University Medical Center Hamburg-Eppendorf (UKE).
The dataset utilized for model training originated from clinical routine at the Department of Nuclear Medicine, UKE.
The attached figure showcases augmented versions for two sample cases from the dataset:
a healthy control case ('normal') and a Parkinson's disease case ('reduced') with reduced availability of DAT in the striatum.
The study addresses the need for reliable and automated classification of DAT-SPECT images,
providing insights into improving diagnostic accuracy,
reducing the burden of misclassifications and minimizing the manual inspection effort.
Link to thesis(12.5 MB)

Autor: Julius Brockmann, betreut von Sebastian Dörrich
This thesis examines the benchmarking of state-of-the-art baseline neural networks in the field of 2D biomedical image classification. Focusing on the effectiveness of deep learning models on high-quality medical databases, the study employs pre-trained baseline networks to establish benchmarks. The research investigates four convolutional neural
networks and one transformer-based architecture, exploring how changes in image resolution affect performance. The findings highlight the advanced capabilities of newer convolutional networks and demonstrate the effectiveness of transformer architectures for handling large datasets. Common misclassifications and their causes are also briefly analyzed, offering insights into potential areas for improvement in future studies.
Link to thesis(8.4 MB)
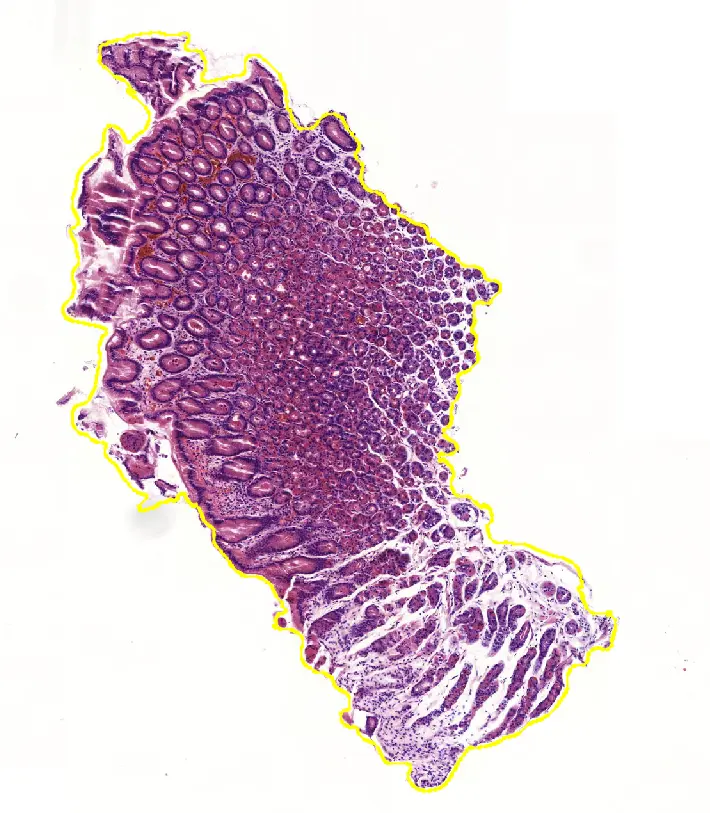
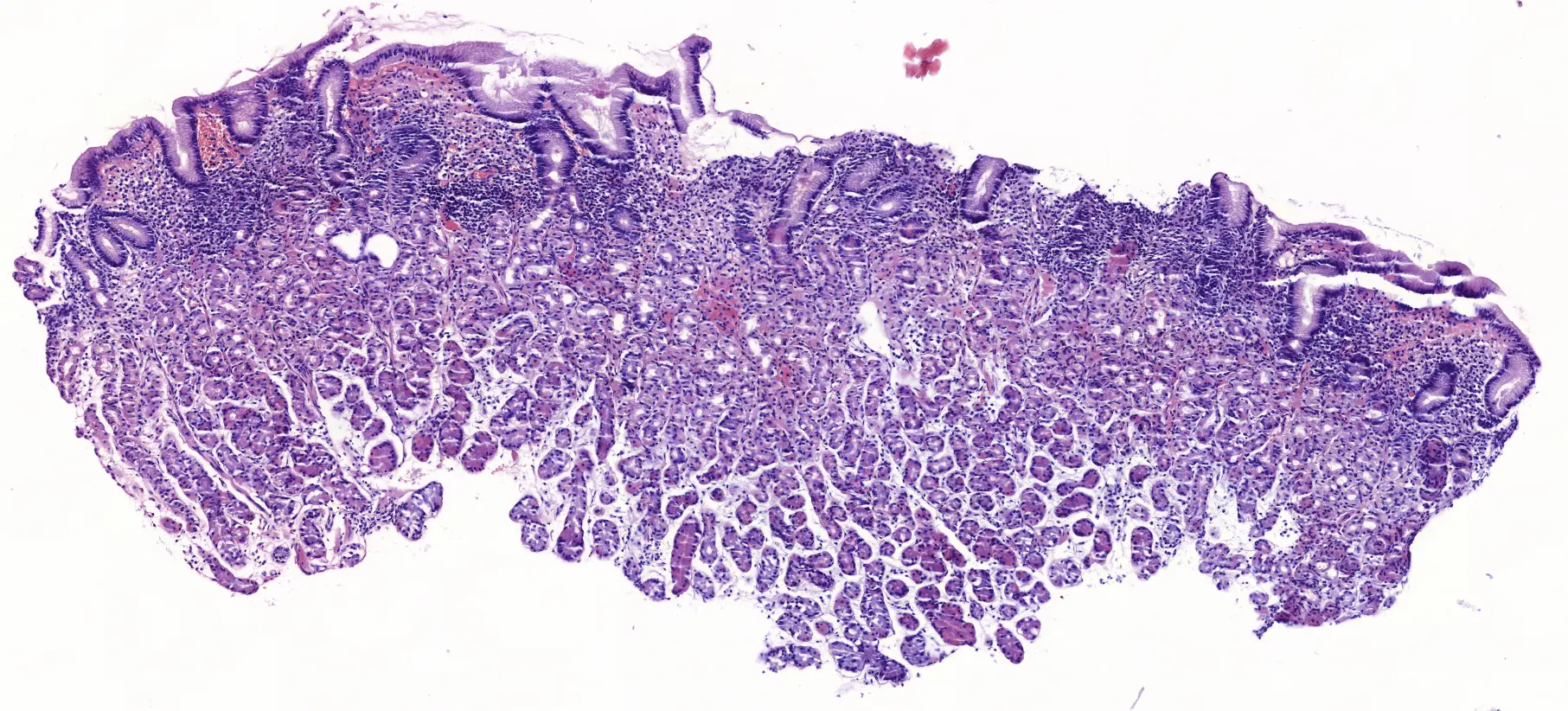
Autor: Tom Hempel, betreut von Prof. Dr. Christian Ledig
The thesis focuses on the development of a dataset and AI algorithms for classifying digitized whole slide images (WSIs) of gastric tissue. It details the creation and meticulous annotation of the dataset, which is crucial for effectively training the AI. The process involved gathering, anonymizing, and annotating a vast array of WSIs, aimed at building robust AI models that can accurately classify different regions of the stomach and identify inflammatory conditions.
Two AI models were developed, one for assessing gastric regions and another for inflammation detection, achieving high accuracy in areas like the antrum and corpus but facing challenges with intermediate regions due to dataset limitations and the specificity of training samples.
The challenges encountered during the dataset creation, such as data collection and the necessity for detailed annotation to ensure data integrity and privacy, highlight the complexity of this research.
The dataset and initial models serve as a foundation for further research by Philipp Andreas Höfling in his master thesis, aiming to refine these AI algorithms and enhance their utility in medical diagnostics.
Link to thesis(5.1 MB)
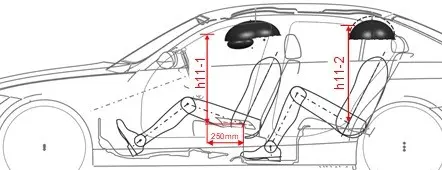
Autor: Tobias Koch, betreut von Prof. Dr. Christian Ledig
Geometric measurements are frequently performed along the virtual vehicle development chain to monitor and confirm the fulfillment of dimensional requirements for purposes like safety and comfort. The current manual measuring process lacks in comparability and quality aspects and involves high time and cost expenditure due to the repetition across different departments, engineers, and vehicle projects.
Thereby motivated, this thesis presents an automated approach to component identification, leveraging the power of Machine Learning (ML) in combination with rule-based filters. It streamlines the geometric measurement process by classifying vehicle components as relevant or not and assigning uniformly coded designations. To determine the most effective approach, the study compares various ML models regarding performance and training complexity, including Light Gradient-Boosting Machines (LightGBMs), eXtreme Gradient Boosting (XGBoost), Categorical Boosting (CatBoost), and Feedforward Neural Networks (FNNs).
The results indicate that the integration of ML models can substainally improve the geometric measurement process in the virtual vehicle development process. Especially LightGBM and CatBoost proved to be the most capable models for this tasks and offer promising progress in the virtual development of vehicles.
Link to the thesis(3.6 MB)
Weitere abgeschlossene Abschlussarbeiten
- "Reproduction of Selected State-of-the-Art Methods for Anomaly Detection in Time Series Using Generative Adversarial Networks" - Anastasia Sinitsyna, betreut von Ines Rieger
- “Feasibility of Deep Learning-based Methods for the Classification of Real and Simulated Electrocardiogram Signals” - Markus Brücklmayr, betreut von Christian Ledig
- “Exploring the Generalization Potential and Distortion Robustness of Foundation Models in Medical Image Classification by Introducing a New Benchmark for the Multidimensional MedMNIST+ Dataset Collection” - Alexander Haas, betreut von Sebastian Dörrich [code] [thesis(23.6 MB)]
- “Deep Learning based Legibility Evaluation using Images of Children's Handwriting" - Aaron-Lukas Pieger, Zusammenarbeit mit Stabilo, betreut von Christian Ledig [thesis(24.5 MB)]
- “Deep Learning based Evaluation of Handwriting Legibility using a Sensor Enhanced Ballpoint Pen” - Erik-Jonathan Schmidt, Zusammenarbeit mit Stabilo, betreut von Christian Ledig [thesis(13.0 MB)]
- “Developing a comprehensive dataset and baseline model for classification and generalizability testing of gastric whole slide images in computational pathology” - Dominic Harold Liebel, betreut von Christian Ledig [thesis(9.3 MB)]
- “Analyzing the Correlation Between Performance and Representational Capability in Foundation Models through CLS Token Inversion and Key Self-Similarity” - Maximilian Jan Grudka, betreut von Sebastian Dörrich
- "Deep Learning Based Assessment of Handwriting Legibility via Pairwise Image Comparisons and Ranking" - Meike Valentina Bauer, betreut von Christian Ledig
- "A comparative Evaluation of Convolutional Neural Network and Vision Transformer Architectures for Medical Image Classification: Reproducing and Improving state-of-the-art methods" - Peter Osterrieder, betreut von Christian Ledig
- “An Empirical Study of Distance-Based Anomaly Detection Methods for Medical Image Analysis on Foundation Model Embeddings” - Aymen Sarsout, betreut von Francesco Di Salvo
- “Evaluating Parameter-Efficient Fine-Tuning Techniques for Vision Foundation Models on the Multi-Modal, Multi-Scale MedMNIST+ Image Classification Benchmark” - Daniel Lukas Würtinger, betreut von Sebastian Dörrich