Universale Cloud-Edge-IoT Orchestration
Das Aufkommen von Internet of Things (IoT) ist eine bedeutende Entwicklung der heutigen Informationstechnologie und umfasst die Fähigkeit von physischen Geräten, Daten über Netzwerke auszutauschen. Häufig werden die generierten Daten in die Cloud übertragen und dort verarbeitet. Ebenso übernimmt die Cloud die Steuerung der Geräte. In Anwendungsbereichen wie Hausautomatisierung, Produktionsteuerung und dem autonomen Fahren ermöglicht dies den Gewinn von neuen Erkenntnissen, effizienterer Nutzung von Ressourcen und einer autonomen Steuerung von Abläufen. Die stets ansteigende Anzahl von datengenerierenden IoT-Geräten führt zu neuen Herausforderungen, die ein Umdenken der bestehenden Cloud-IoT-Architektur erfordern. Dem umfangreichen Datenaufkommen stehen begrenzte Rechen- und Speicherkapazität sowie limitierte Bandbreite zum Transfer der Daten in die Cloud entgegen. Kernherausforderung ist zudem die Reduzierung der Kommunikationslatenz zwischen Cloud und IoT-Geräten zur Ermöglichung von Echtzeitverarbeitung in Anwendungsbereichen wie Virtual Reality oder Smart Cities.
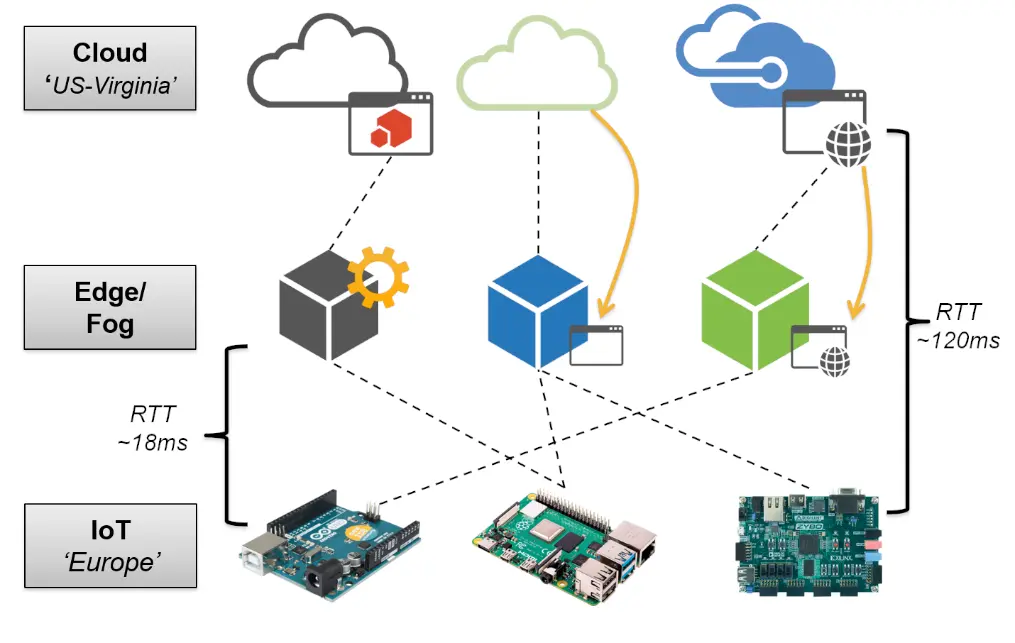
Edge-Computing stellt einen Lösungsansatz für diese neuen Ansprüche durch Bereitstellung von Rechen- und Speicherkapazität in geografischer Nähe zu IoT-Geräten dar. Abbildung 1 zeigt mögliche Bereitstellungsformen der Edge-Schicht, nämlich (i) als einen zusätzlichen Vorverarbeitungsschritt zwischen IoT und Cloud, (ii) als vollständigen Ersatz zur Cloud und (iii) als zusätzliche Unterstützungsschicht. Durch die zusätzliche Bereitstellung kann eine deutliche Reduktion der Kommunikationslatenz erreicht werden.
Die Datenverarbeitung in Cloud und Edge wird meist in Form von leichtgewichtigen Containern verfügbar gemacht. Die reduzierte Größe von Containern im Vergleich zu virtuellen Maschinen (VM) ermöglicht eine flexible Bereitstellung auf verschiedenen Ebenen der Cloud-Edge/Edge-IoT Architektur. Hierbei gilt es eine effiziente Verteilung der containerisierten Applikation zu erreichen, um:
- dem (oft limitierten) Angebot an Ressourcen der Geräte (z. B. Raspberry Pi oder andere Embedded-Geräte) im Edge-Layer gerecht zu werden und den Energieverbrauch durch effiziente Verteilung zu minimieren
- die Anforderungen an die benötigte Latenz der Applikation und der verfügbaren Bandbreite zu erfüllen
- alle Abhängigkeiten zu anderen Services und weiteren Ressourcen entsprechend in annehmbarer Distanz zum eigentlichen Service bereitzustellen.
Für die Frage der Verteilung von containerisierten Applikationen spricht man von der sog. Cloud-Edge Orchestration, die sich diesen Herausforderungen annimmt. Die Orchestration einer solchen mehrschichtigen Architektur umfasst die Auswahl von Edge-Knoten für das Deployment, Monitoring und die autonome und dynamische Ausführung von Containern unter Einhaltung der geforderten Quality-of-Service (QoS), wie z.B. die maximal zulässige durchschnittliche Verarbeitungszeit einer Anfrage. Neben populären Frameworks wie Kubernetes gibt es zahlreiche weitere, nicht-threshold basierte Algorithmen und Policies zur Umsetzung komplexer autonomer Orchestrationen mit unterschiedlichen Techniken z. B. aus dem Bereich des maschinellen Lernens.
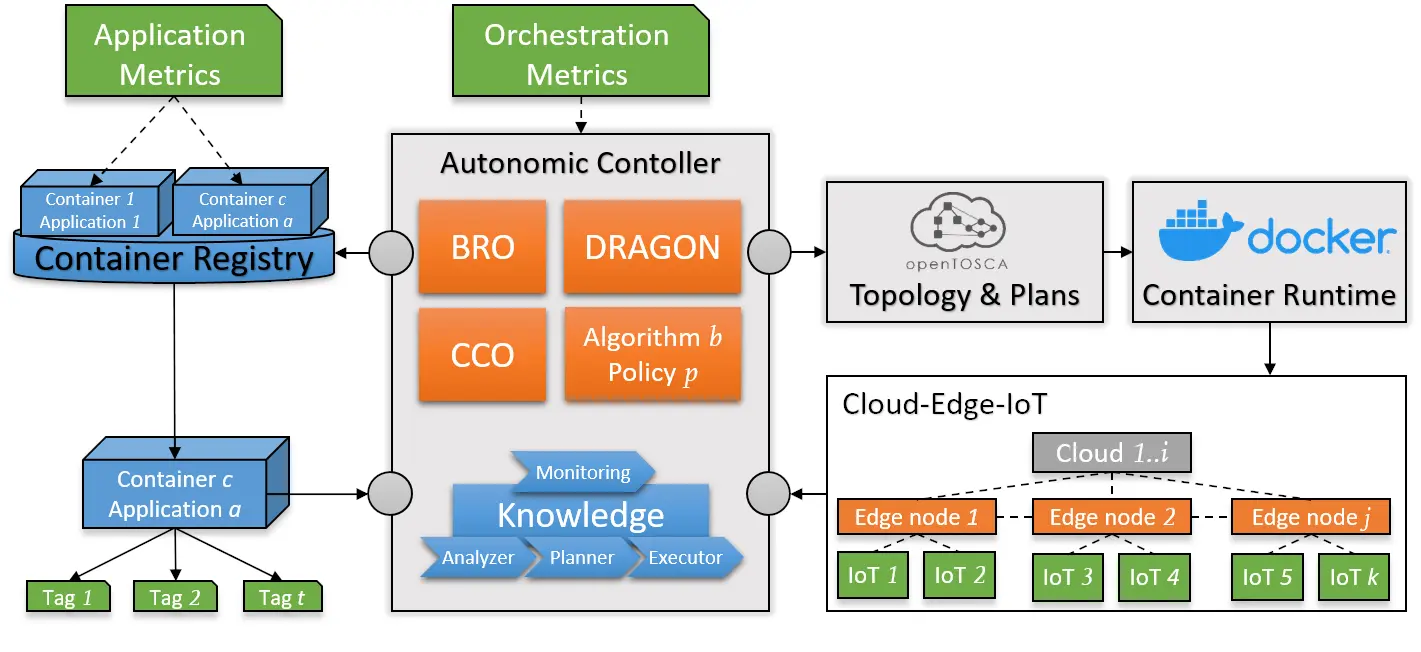
Ziel ist es, basierend auf dem Leistungsanforderungsprofil von Applikationen (z.B. CPU- oder I/O-intensiv) und Infrastrukturleistungsdaten, wie z.B. Art und Anzahl der Knotenpunkte, einen Algorithmus für eine autonome Orchestration auszuwählen. Die Orchestration wird dabei in eine plattform-unabhängige Orchestrationstopologie umgesetzt und von einer Container-Runtime (z. B. Docker) ausgeführt und anschließend auf Knoten in der Cloud-, Edge- und IoT-Ebene verteilt. Die Knotenpunkte melden dabei stets QoS-Daten an den Autonomen Controller zurück, welcher unter Anwendung des MAPE-K-Loop reagiert und die Orchestration laufend anpasst (Abb. 2). Anhand der gewonnenen Daten kann mit Hilfe statistischer Auswertungen eine Empfehlung für die zukünftige Bereitstellung von neuen Applikationen ausgesprochen werden.
Aus diesem universalen Architekturvorschlag ergeben sich folgende Fragestellungen, welche im Kernbereich unserer Forschung stehen:
Unser Ziel ist es, basierend auf bereits populären Container Orchestrations-Plattformen wie Kubernetes und anderen Plattformen bzw. Technologien eine abstrahierte, konfigurierbare und vereinfachte Verwaltung von Cloud-Edge/Edge-IoT Architekturen zu realisieren um die Nutzung von Edge-Computing für noch mehr Anwendungsbereiche und Nutzer einfacher möglich zu machen. Die weitere Durchdringung von Edge-Computing in bestehenden IT-Architekturen kann zu transparenterem Datenschutz, geringerem Energieverbrauch für die Bereitstellung von Infrastruktur und höherer Endnutzerzufriedenheit führen.
Beteiligte Mitarbeiter:
Publikationen
Böhm S., Wirtz G.: Towards Orchestration of Cloud-Edge Architectures with Kubernetes
EAI Edge-IoT 2021 - 2nd EAI International Conference on Intelligent Edge Processing in the IoT Era, online virtual congress, 24-26 November 2021
Böhm S. and Wirtz G.: Profiling Lightweight Container Platforms: MicroK8s and K3s in Comparison to Kubernetes
Proceedings of the 13th Central European Workshop on Services and their Composition, Bamberg, Germany, February 25-26, 2021.
Böhm, S. and Wirtz, G.: A Quantitative Evaluation Approach for Edge Orchestration Strategies
Service-Oriented Computing, Springer International Publishing, 2020, 127-147.