Universal Cloud-Edge-IoT Orchestration
The emergence of Internet of Things (IoT) is a significant development in today's information technology and involves the ability of physical devices to exchange data over networks. Often, the generated data is transferred to the cloud and processed there. Likewise, the cloud takes control of the devices. In application areas such as home automation, production control and autonomous driving, this enables the gain of new insights, more efficient use of resources and autonomous control of processes. The ever-increasing number of data-generating IoT devices is creating new challenges that require modifications of the already existing Cloud-edge architectures. The large volume of data is countered by limited computing and storage capacity, as well as limited bandwidth to transfer the data to the cloud. Another key challenge is to reduce the communication latency between cloud and IoT devices to enable real-time processing in application areas such as virtual reality or smart cities.
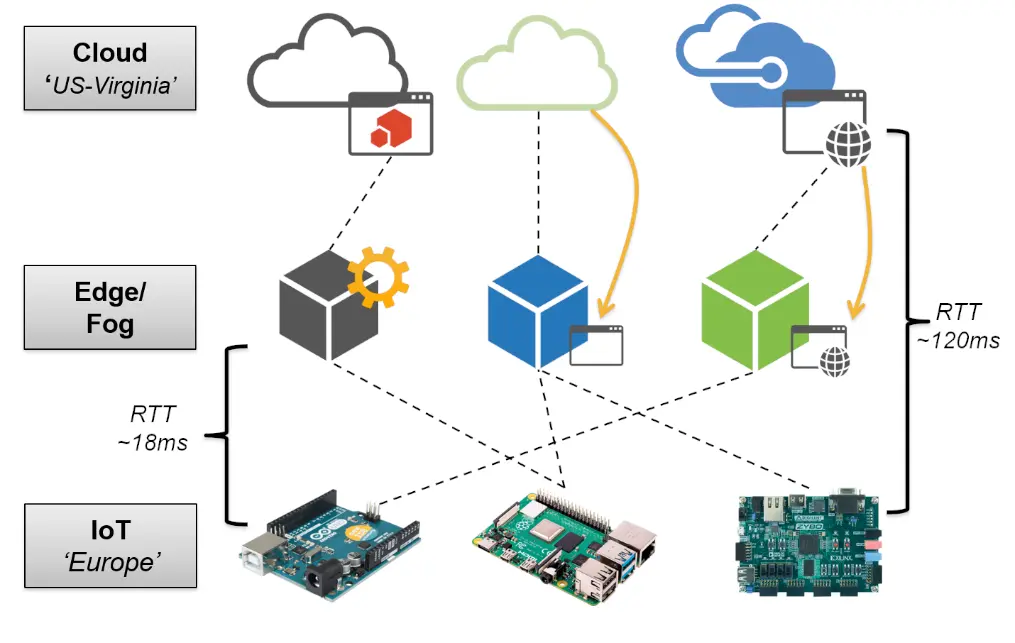
Figure 1 shows possible ways to implement the edge layer, namely (i) as an additional pre-processing step between IoT and cloud, (ii) as a fully replacement to the cloud, and (iii) as an additional support layer. In general, the additional deployment can achieve a significant reduction in communication latency.
Data processing in cloud and edge is mostly realized by usage of lightweight containers. The reduced size of containers compared to virtual machines (VM) enables flexible deployment at different layers of the cloud-edge/edge-IoT architectures. It is essential to achieve an efficient distribution of the containerized application in order to:
- meet the (often limited) resources of the devices (e.g. Raspberry Pi or other embedded devices) in the edge layer and minimize energy consumption through efficient distribution
- meet the requirements latency and bandwidth of applications
- provide all dependencies to other services and further resources accordingly in acceptable distance to the actual service.
The term orchestration addresses the challenges in distributing containerized applications to the different layers. The orchestration of such a multi-tier architecture includes the selection of edge nodes for deployment, monitoring and the autonomous and dynamic execution of containers while complying with the required Quality-of-Service (QoS), such as the maximum allowed average processing time of a request. In addition to popular frameworks such as Kubernetes, there are various other non-threshold-based algorithms and policies for implementing complex autonomous orchestrations using various techniques, e.g., from the field of machine learning.
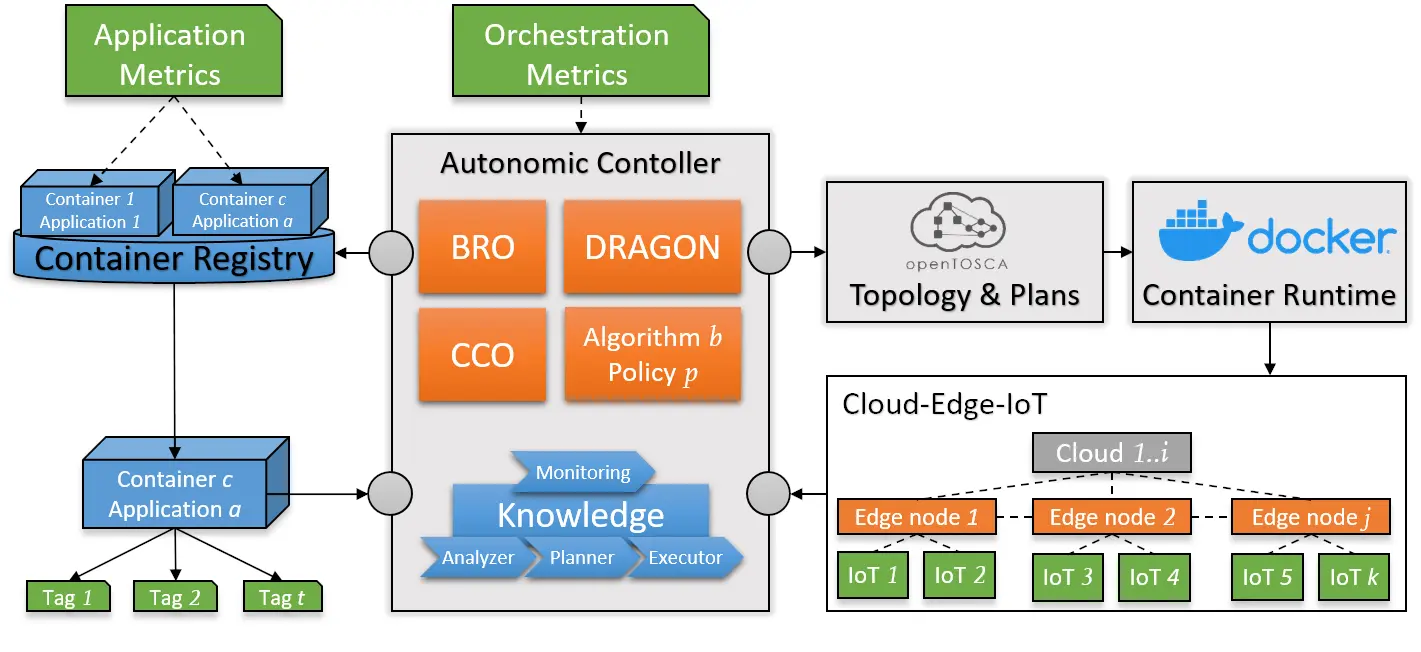
The goal is to select an algorithm for an autonomous orchestration based on the performance requirement profile of applications (e.g., CPU or I/O intensive) and infrastructure performance data, such as type and number of nodes. The orchestration is thereby implemented in a platform-independent orchestration topology and executed by a container runtime (e.g., Docker) and then distributed to nodes in the cloud, edge and IoT layers. The nodes are reporting QoS data back to the Autonomous Controller, which responds by applying the MAPE-K loop and continuously adapts the orchestration (Figure 2). Based on the obtained data, statistical analysis can be used to make a recommendation for the future deployment of new applications.
This universal architectural proposal leads to the following questions, which are in focus of our research area:
We aim to realize an abstracted, configurable and simplified management of cloud-edge/edge-IoT architectures based on already popular container orchestration platforms like Kubernetes and other platforms and technologies to make the use of edge computing easier for even more application areas and users. The further penetration of edge computing in existing IT architectures can lead to more transparent data protection, lower energy consumption for the provision of infrastructure and higher end-user satisfaction.
Participants:
Publications
Böhm S., Wirtz G.: Towards Orchestration of Cloud-Edge Architectures with Kubernetes
EAI Edge-IoT 2021 - 2nd EAI International Conference on Intelligent Edge Processing in the IoT Era, online virtual congress, 24-26 November 2021
Böhm S. and Wirtz G.: Profiling Lightweight Container Platforms: MicroK8s and K3s in Comparison to Kubernetes
Proceedings of the 13th Central European Workshop on Services and their Composition, Bamberg, Germany, February 25-26, 2021.
Böhm, S. and Wirtz, G.: A Quantitative Evaluation Approach for Edge Orchestration Strategies
Service-Oriented Computing, Springer International Publishing, 2020, 127-147.