The two tags, isn’t it and right are analyzed in four written English corpora, namely Brown and Frown for American English, and LOB and F-LOB for British English. Furthermore, the study is based on the DCPSE, a corpus of spoken British English, containing material from LLC and ICE-GB, which both comprise roughly 400.000 words. While the corpora of the Brown family work with the WordSmith software, the ICECUP program is needed for the DCSPE.
In WordSmith, the “Concord” function is chosen (cf. Screenshot 1). Brown, Frown, LOB and F-LOB are examined one after the other, which means that all sections of the Brown corpus are chosen first (cf. Screenshot 2). Then, isn’t it is typed into the search mask (cf. Screenshot 3) and a concordance list is obtained (cf. Screenshot 4). The texts of the Brown corpus remain selected and the same procedure is repeated with the search word right. As isn’t it and right are not only question tags, but can come up in a number of different contexts, it is necessary to go through all the instances in the concordance lists manually and to delete the examples which do not contain a question tag in order to finally end up with the relevant corpus examples. After the analysis is finished in the Brown corpus, the same steps are repeated in the other three corpora which work with WordSmith.
Screenshots for the corpus analysis in WordSmith:
Screenshot 1: The “Concord” function in WordSmith
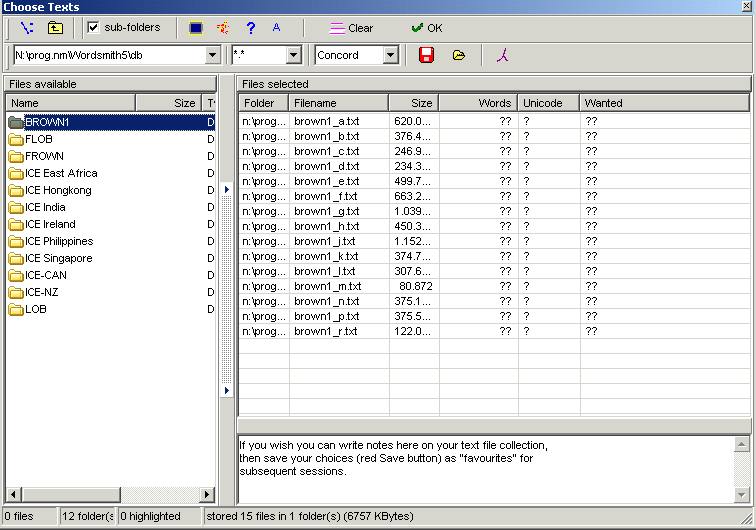
Screenshot 2: The corpora of the Brown family in a list amongst others on the left-hand side and the texts of Brown selected for the analysis on the right-hand side
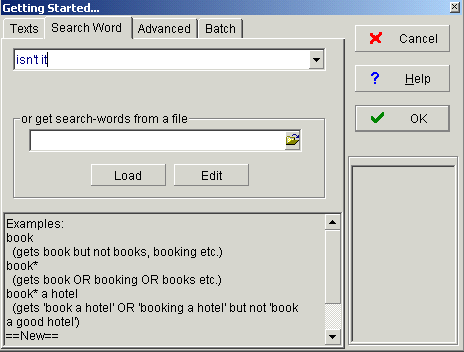
Screenshot 3: The tag isn’t it as search word
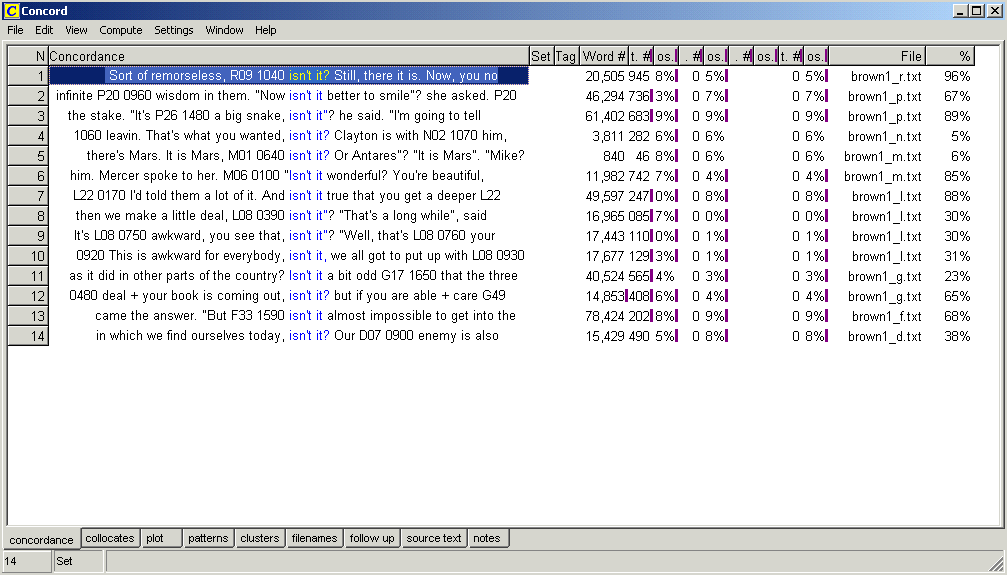
Screenshot 4: Concordance list for the search word isn’t it in Brown
For the DCPSE, the same search procedure is maintained. In order to distinguish between LLC and ICE-GB in the search, the “SOURCE CORPUS” function is chosen from the drop-down menu in ICECUP (cf. Screenshot 5). First, LLC is selected and isn’t it is typed into the search mask (cf. Screenshot 6). A concordance list is obtained (cf. Screenshot 7) and the examples in which isn’t it does not function as a question tag are eliminated. Then, right is typed in as search word and the steps explained above are repeated. Finally, ICE-GB is chosen and the procedure is carried out one more time in the second part of the spoken corpus.
Screenshots for the corpus analysis in ICECUP:
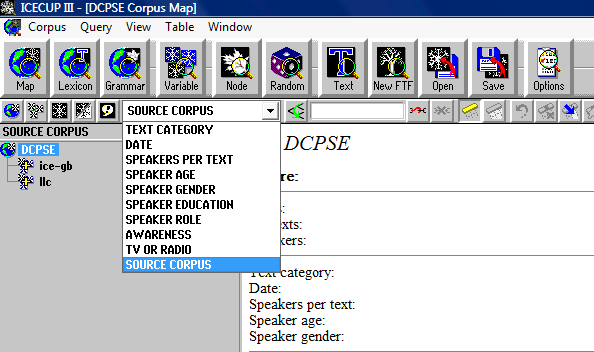
Screenshot 5: The option “SOURCE CORPUS” is selected in the down-down menu and the different parts of the DCPSE become visible on the left-hand side
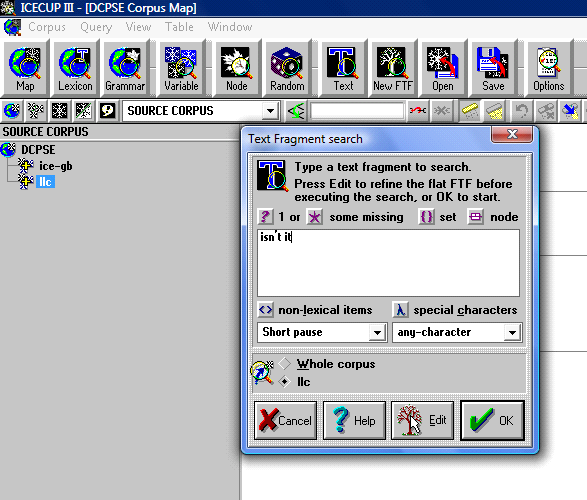
Screenshot 6: Isn’t it is searched for in LLC
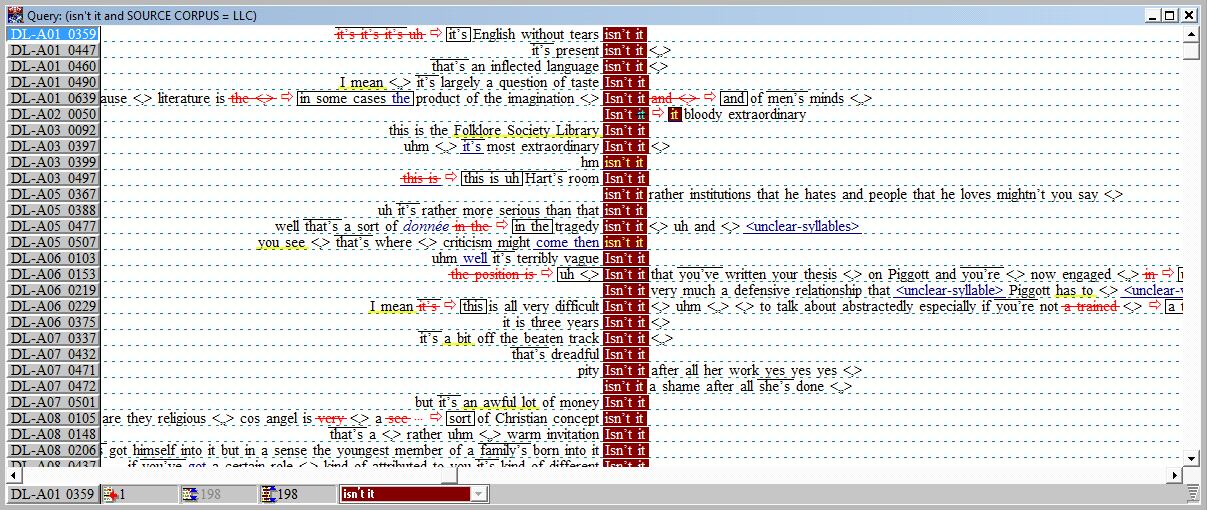
Screenshot 7: Concordance list for the search word isn’t it in LLC
As isn’t it and right can not only be question tags, but do occur in different functions in a sentence, precision is not perfect with this search procedure. Recall is high, as all the instances containing the tags isn’t it or right are found in the corpora.
6.4.1 Example sentences from the corpora
6.4.2 Results and conclusions
Created with the Personal Edition of HelpNDoc: Easily create HTML Help documents