KI2020: Fast Pathfinding in Knowledge Graphs Using Word Embeddings
by Leon Martin, Jan H. Boockmann, and Andreas Henrich
Abstract
Knowledge graphs, which model relationships between entities, provide a rich and structured source of information. Currently, search engines aim to enrich their search results by structured summaries, e.g., obtained from knowledge graphs, that provide further information on the entity of interest. While single entity summaries are available already, summaries on the relations between multiple entities have not been studied in detail so far. Such queries can be understood as a pathfinding problem. However, the large size of public knowledge graphs, such as Wikidata, as well as the large indegree of its major entities, and the problem of concept drift impose major challenges for standard search algorithms in this context.
In this paper, we propose a bidirectional pathfinding approach for directed knowledge graphs that uses the semantic distance between entity labels, which is approximated using word vectors, as a search heuristics in a parameterized A*-like evaluation function in order to find meaningful paths between two entities fast. We evaluate our approach using different parameters against a set of selected within- and cross-domain queries. The results indicate that our approach generally needs to explore fewer entities compared to its uninformed counterpart and qualitatively yields more meaningful paths.
Introduction
- Knowledge graphs encode entities of the real world (nodes) and their relations (edges) taken from various domains in a graph representation
- Google uses their knowledge graph to generate knowledge panels for single entity queries (see right)
- The construction of knowledge panels for dual-entity query can be understood as pathfinding in knowledge graphs
- While pathfinding in knowledge graphs is trivial for adjacent entities, there are problems regarding distant entities:
Knowledge graphs are huge
→ Naive algorithms do not suffice for pathfinding
→ Interfaces may struggle to deliver all edges of a queried entity
When the semantic focus is left, concept drift arises
→ Users want meaningful paths
Shorter paths are not necessarily more meaningful
→ We need an appropriate search heuristics to guide our search
Hence, in our paper we investigated the following research question:
Does a bidirectional search algorithm using the semantic distance as a search heuristics lead to meaningful paths in KGs fast?

The Algorithm
The employed pathfinding algorithm on the left reflects the design choices we made to apply the A* algorithm to our problem. We noticed that many entities possess a number of incoming edges that exceeds the limits of Wikidata's SPARQL interface. To maximize the number of paths that the algorithm can find without running into a timeout we perform two searches simultaneously, one from the source entity to the target entity and vice versa. When an intersection is found, a path has been found. To ensure that the entity with the lowest costs is always explored next we use a shared priority queue that enumerates the candidates with respect to their score according to our search heuristics.
The Search Heuristics
The search heuristics is the essential component of a best-first search algorithm like A*. Our search heuristics leverages the semantic distance between a candidate entity and the source/target. We estimate this abstract metric as the cosine distance between the word vectors of the entity labels. For robustness, we employ the pretrained models of fastText because they are able to produce vector representations of words that are not present in the training data.
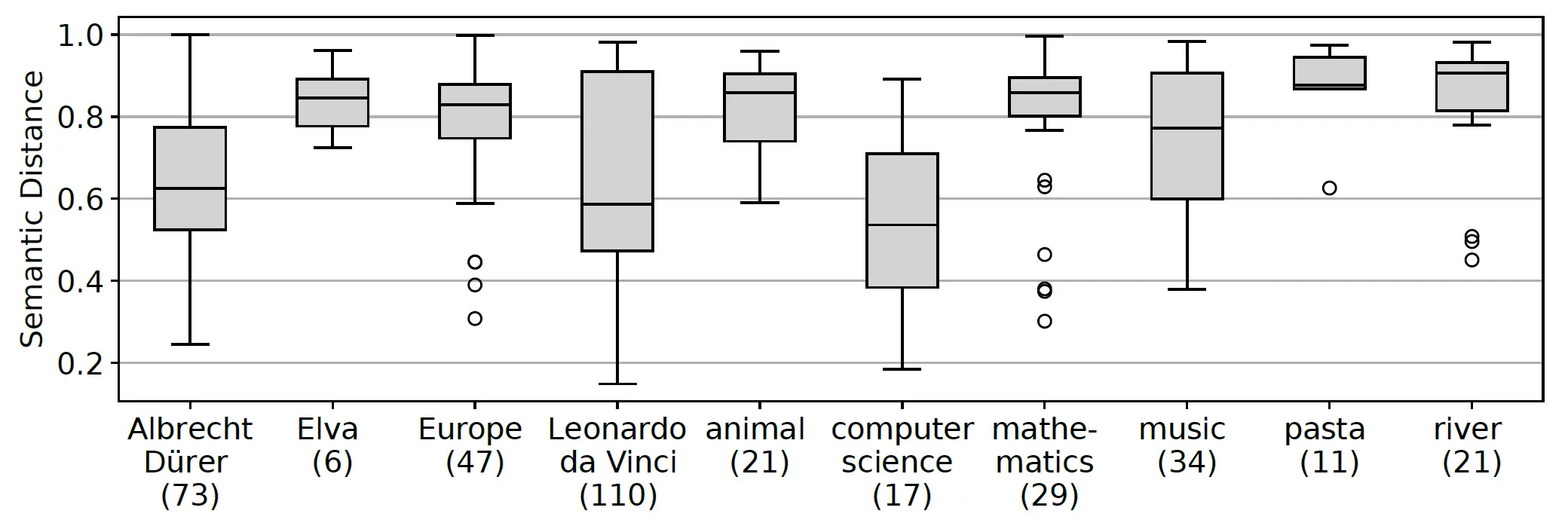
Our approach is based on the assumptions that the semantic distance varies between adjacent entities and that entities in proximity show a lower semantic distance on average. The figure below shows the distribution of the semantic distance for a selection of sample entities. Note that the semantic distance is broadly distributed indicating that some neighboring entities are indeed more worthwhile to pursue than others.
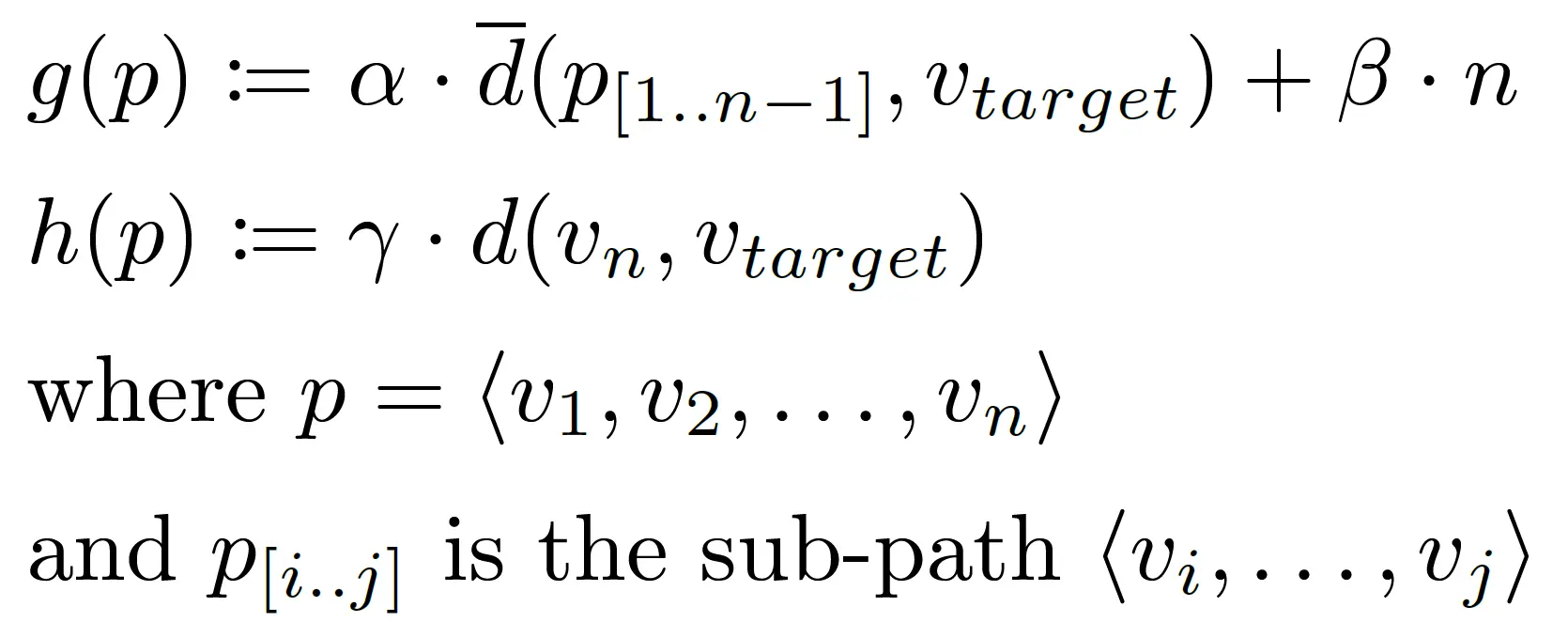
We consider paths meaningful that minimize the average semantic distance to the target, i.e., preventing concept drift. Hence, inspired by a general A* evaluation function, the function f(p) = g(p) + h(p) denotes the costs of a path p with length n as shown on the right. Formula d_bar(p[1..n-1], vtarget) calculates the average of the semantic distances between each entity on the path - excluding the last one - and the target entity. Formula d(vn, vtarget) estimates the semantic distance between the last entity and the target entity. Note that this approach is a heuristic adaptation of the A* idea.
The parameters in the evaluation function allow for weight adjustments. Since there is no testing data for our particular task, no parameter fitting could be performed. Instead, we came up with four configurations that focus on different aspects:
- Uninformed (α = ɣ = 0, β = 1) neglects the semantic distances and only considers the prior path length, thus representing a baseline.
- Semantics-Only (α = ɣ = 1, β = 0) ignores the path length and only considers the semantic distances.
- Greedy (α = β = 0, ɣ = 1) does not consider prior path length and average semantic path costs, and estimates the remaining path costs using the semantic distance of the last entity to vtarget.
- Balanced (α = ɣ = 1, β = 0.5) takes semantic distances and path length into account; β < 1 reduces the impact of path length on the overall costs.
Evaluation
The table below shows the benchmark results for within- and cross-domain queries from vsource to vtarget (entity label and Wikidata entity identifier) using the four evaluation function configurations. We provide information on the length of the found path (l) measured in the number of entities including source and target, and use symbols in superscript to denote difference/equivalence among paths in the same row; we report on the number of explored entities (c) and the total runtime in seconds (t).
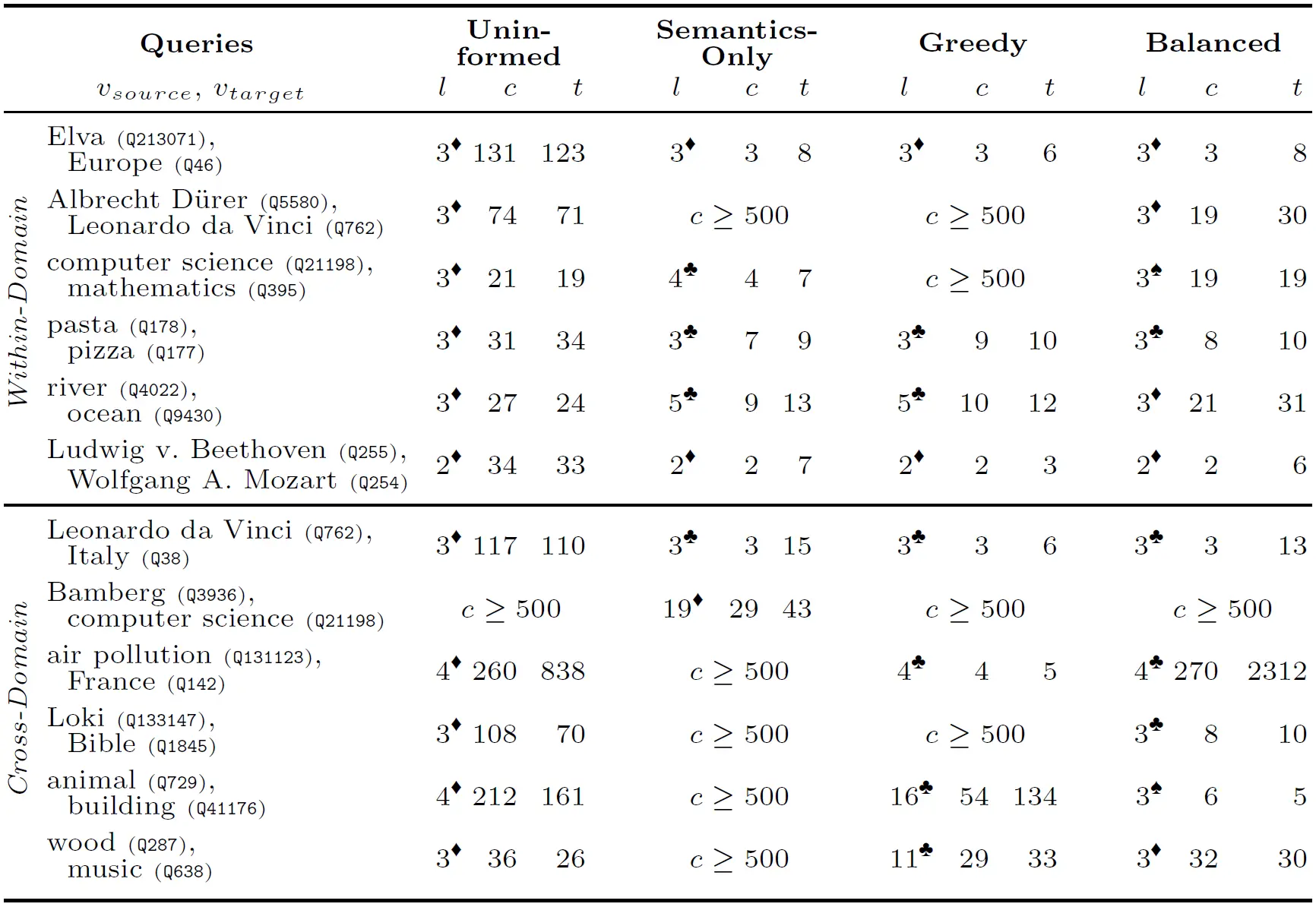
Interesting observations:
- Every query can be answered by at least one configuration that considers the semantic distance
- The configurations Uninformed and Balanced yield the best coverage of the query set
- The Balanced configuration needs to explore fewer entities to find a path and is also faster on average when excluding the outlier query from "France" to "air pollution"
- Despite the additional time necessary to properly enqueue elements into the priority queue, the runtime performance of any informed configuration is better than the uninformed configuration on average when ignoring forcefully stopped searches
- Answering cross-domain queries require more time since more entities have to be explored
Hence, the semantic distance appears to be a viable search heuristics to find paths in a large KG fast.
Regarding meaningfulness:
- A qualitative analysis of the found paths showed that the informed configurations can produce useful paths
(e.g. "Elva" → "Estonia" → "Europe" and "pasta" ← "flour" ← "pizza") - Other paths contained entities (e.g. encyclopedias) of debatable meaningfulness
The results motivate further investigation but to properly assess the meaningfulness of paths user studies are required.